Leios - An Overview
For the last 6 months or so, Sundae Labs has been working together with Input Output and Well-Typed to study and refine the design of Ouroboros Leios, a proposed upgrade to the Cardano consensus mechanism. Leios is a protocol whose security is already well understood, but having confidence in the security of a protocol is a long way from knowing exactly how to build, deploy, and parameterize it.
We’ve written a Rust simulation that has been helping the IO team do deep analysis on the behavior of the protocol at scale: what is the network-wide CPU utilization, what is the average time until a transaction gets included in a block, and how do these (and other) metrics vary when you vary the protocol parameters that you configure Leios with.
Through that process, we’ve fallen in love with the protocol: it truly is an impressive and subtle piece of protocol design that offers massive opportunities for the Cardano network to meet its scalability and sustainability goals. Like most things in computer science, however, it necessarily comes with trade-offs, and now that we are in an era of on-chain governance, the DReps and broader community will need to have some serious conversations about the nature of these tradeoffs, and how exactly to deploy Leios.
It’s also important for those conversations to be centered around a deep understanding of the facts of those tradeoffs. Otherwise, imprecise understanding can lead to alarmism, misinformation, and ultimately incorrect and damaging decisions made by DReps.
My hope in writing this blog post is to very simply explain a number of truths about Leios in an approachable way to meet that need. The goal has always been to build and design Leios in an open and inviting way: the team hosts monthly review meetings, the work is being done open source on github, and the team is always more than happy to answer questions and solicit ideas from the community. In particular, you can find weekly writeups and daily logs in the Weekly Updates or the developer Logbook on GitHub.
This blog tries very hard to strike a balance between giving a good, high-level understanding of the protocol for non-technical users, while not shying away from or hand-waving away deeply technical subtleties. It should be fine to skip over the more technical parts of this post. If you ever feel I navigated that indelicately, or if you want additional clarity on anything, please feel free to reach out to me by email, at pi@sundae.fi. I’ll do my best to answer and may write a follow-up blog post answering some of those questions.
Finally, I should emphasize: that Leios is still being designed; very little has been concretely finalized, and now, over the next several months as we prepare for implementation, is the perfect opportunity to provide your input on the design. The team working on it doesn’t claim to have all the answers, and if you have suggestions or clever, out-of-the-box ideas, we’re happy to hear them and help you explore what properties such a solution would have. Here are a couple of guiding principles that would help this (and most other) conversation be most productive:
- Start with “what happens if you…” questions, rather than “why not just…” questions. While we by no means claim to have all the answers and may have missed even simple solutions, members of the team have also been thinking about this problem for months and in some cases years; many of the “obvious” adjustments are likely to have been considered already. Starting from a “what happens if you…” question will help you get to an understanding of the protocol faster.
- Try to write down your proposed solution as precisely as you can, and articulate what specifically it solves. It’s incredibly tough to completely specify a protocol in full detail, but having a strong working understanding yourself helps the discussion be more productive.
- Assume good faith; We all share a common goal: ensure the success, adoption, security, and sustainability of the Cardano blockchain for decades to come. Intelligent people can and will disagree on how to get there, or which trade-offs are acceptable along the way. The best way to get there, however, is with hearty, nuanced discussions that we could all grab a pint together afterward, rather than discussions that escalate and drive hate and animosity within the community.
With all that out of the way, here is an outline of the rest of this blog post:
- Why Leios?
- Review of Ouroboros Praos
- Building up to Leios
- Ouroboros Leios
- Leios Performance and Tradeoffs
- Transaction Conflict
- Closing thoughts
(I’d also like to acknowledge the rest of the Leios team, my team at Sundae Labs, and all of my fantastic beta readers for their feedback. This blog post went through nearly a month of revisions and in some places is unrecognizable from what I originally wrote, for the better.)
Why Leios?
Sustainability
The Cardano network is operated by roughly 3000 stakepools. Each of those, if it’s following recommended best practices, is at least 3 servers: one that produces blocks, and two that act as “relays”, forwarding transactions and blocks around the network. In return, each epoch (which lasts 5 days) an average of 1000 of those nodes produce a block, and receive a cut of the rewards for that epoch.
Those consist of a “small” monetary expansion, and fees paid by each transaction.
As of this writing, the monetary expansion parameter is set to 0.3%. That currently amounts to 21.8 million ADA per epoch.
Similarly, from epochs 500 to 550, we’ve seen an average of 270 thousand transactions per epoch, each of which contributes an average of 0.34 ADA, for an average of 93,000 ADA per epoch in fees.
Of the nearly 21.9 million ADA collected from these two sources, 20% is sent to the treasury. Then, because of unstaked ADA and pools missing blocks, a significant portion (an average of 9.7 million ADA) is returned to the reserves. The remainder (an average of 7.7 million ADA per epoch) is distributed among stakepools and their delegators in proportion to their performance.
On average, of the 7.7 million ADA of reserve emissions distributed as staking rewards each epoch, roughly 21% (1.6 million ADA) goes to the stake pool operators, and the rest is distributed to delegators on the network.
Over time, the 7.7m ADA per epoch will decline, decreasing profitability for running a node. The ideal scenario is for the transaction volume to increase correspondingly to replace it and maintain the same profitability. Here’s a chart of the projected rewards paid to a stake pool operator from the reserves over time:
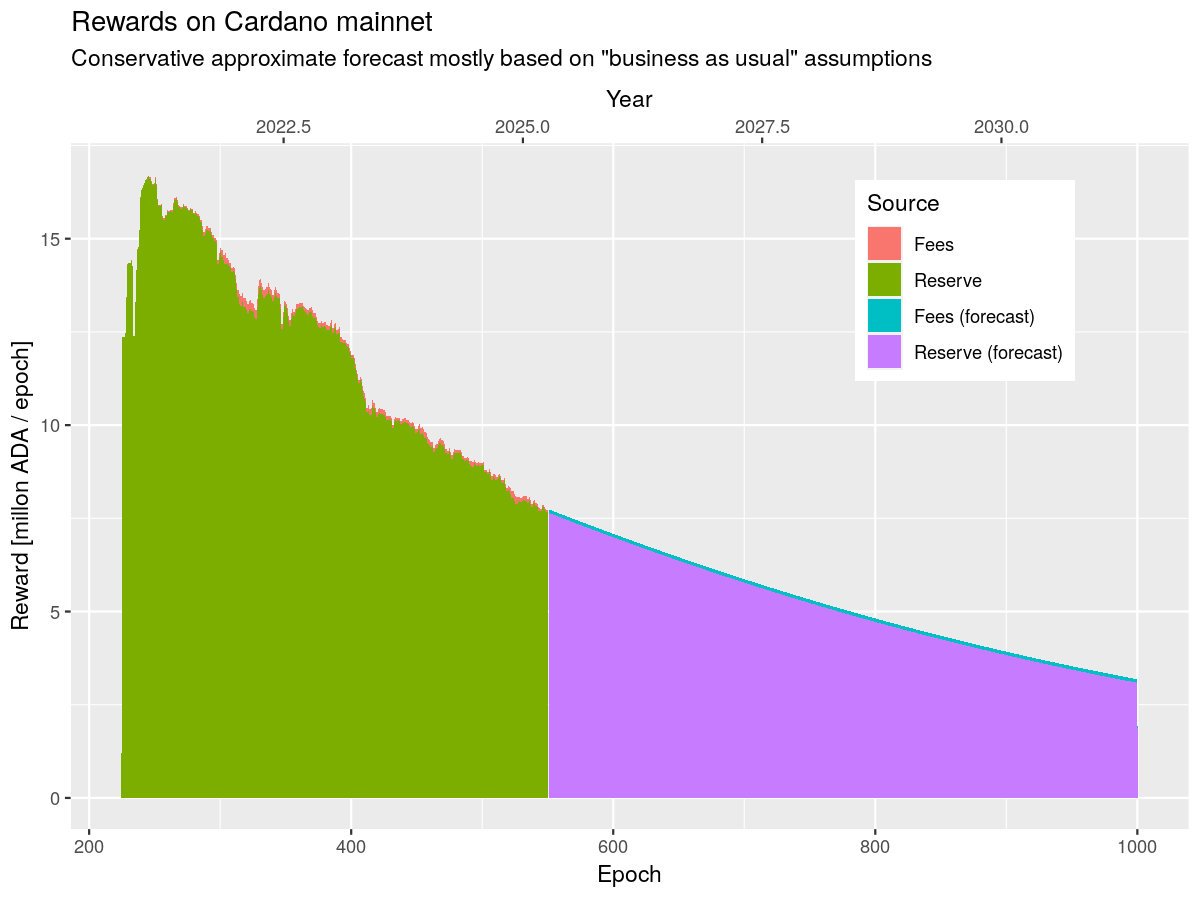
However, at 0.34 ADA per transaction, that would mean that in order to maintain the same profitability, the network would need to process 21.6 million transactions per epoch, or 50 roughly transactions per second. It’s estimated that the current peak throughput for the network, under ideal conditions, is around 10 transactions per second. Here’s a chart of the estimated profitability (revenue as a percentage of estimated expenses) at different throughputs, considering only the income from transaction fees:
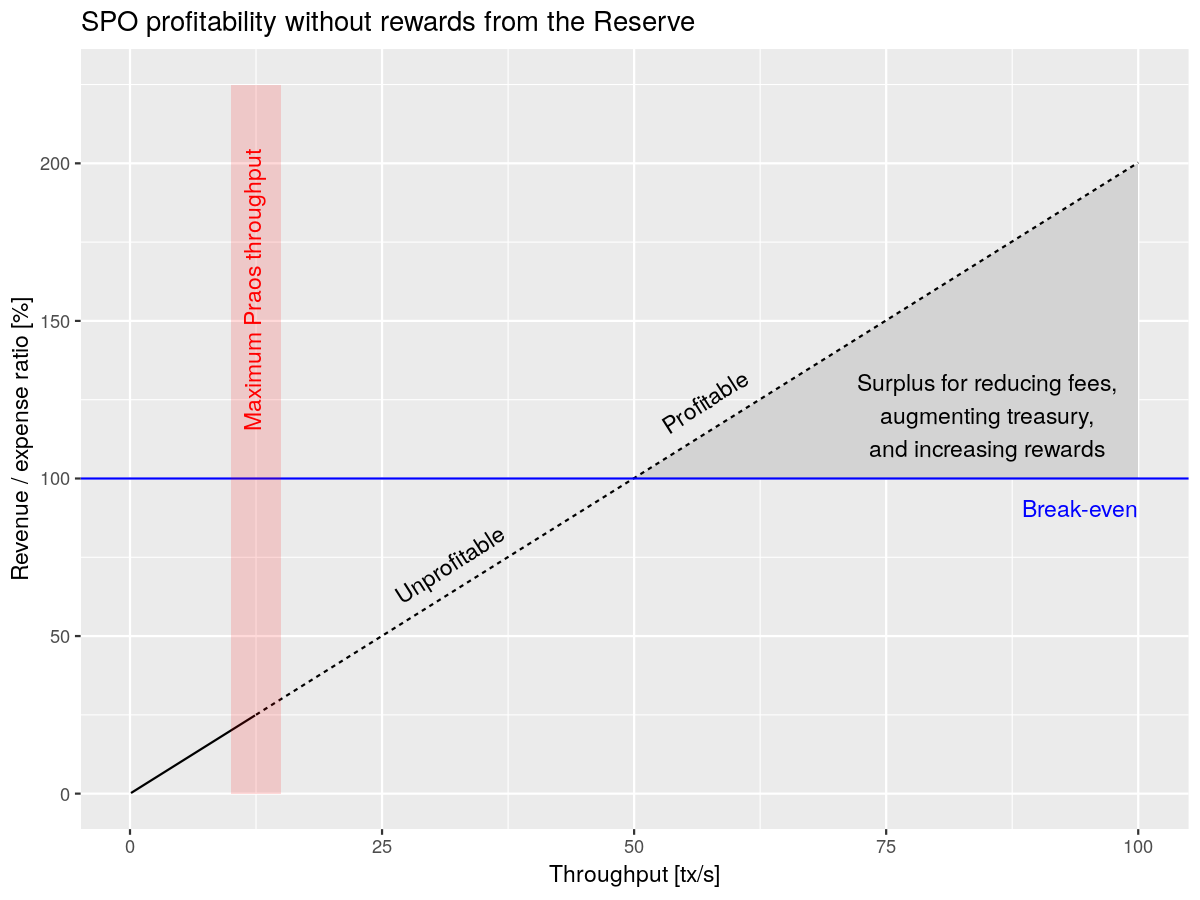
Note that the red region is the estimated maximum throughput for the current Cardano protocol, called Ouroboros Praos.
And, don’t forget, users will likely expect the cost per transaction to go down over time, to remain competitive with other networks.
Thus, if left unaddressed, the Cardano network will likely reach an inflection point where it becomes less and less economically viable to run a node. This is a problem that very very few networks, if any, have solved for the long term. This could turn into a vicious cycle that undermines many of the unique selling points we all value Cardano for, such as its decentralization.
There are several options to ensure the network can pay its bills:
- The price of ADA increases over time
- This would mean that smaller absolute rewards would go further towards paying those bills.
- Hardware improvements or optimizations in the node software decrease the cost of running a node.
- For example, initiatives like UTxO-HD which reduces the required RAM, or alternative node implementations (like Amaru) that prioritize lower hardware requirements can help reduce costs dramatically.
- Operating a stake pool becomes profitable for other reasons
- This is the “Actively Validated Services” model, in which running a stake pool is an essential part of providing services to other use cases. For example, running a stake pool allows you to become a Midnight network operator, earning additional rewards from the Midnight network.
- We replenish the reserves, bringing rewards back up
- For example, if the Cardano treasury is able to profitably invest its 1.5 billion ADA and generate an ongoing yield, a portion of the treasury could be used to replenish the reserves so that rewards remain higher for longer
- The total demand for transactions on the Cardano network rises dramatically
- More transactions would mean more transaction fees, which can replace the reserve emissions. However, in order for this to be meaningful, the Cardano network would need increased capacity.
Given the relative severity of the problem, the Cardano Roadmap calls for delivering on all of the above solutions, and Leios is the leading proposal for how to increase network capacity. With enough increase in capacity (and a corresponding increase in demand), we can both sustain the costs of the Cardano network, and decrease the average fee per transaction in conjunction. Ouroboros Leios offers, in my opinion, the best chance of achieving that while maintaining so much of the hard-won decentralization and determinism that we value on Cardano.
An important note on the above, however, is that Leios alone doesn’t directly solve the problem above: increased capacity means nothing if we don’t have the demand to fill that capacity. It is absolutely critical that we abolish a “build it and they will come” mentality. Leios creates the ability for us to solve this problem, but it is equally, if not more important that we have a corresponding push for real-world business adoption of the Cardano network.
Censorship Resistance
Even separate from the above sustainability concerns, Leios solves a core censorability / availability problem that has deterred some applications from building on Cardano.
Specifically, when the Cardano network is under significant load, it severely impacts everyone’s ability to get time-sensitive transactions on-chain. Currently, this is fair, because it impacts everyone equally; however, as the protocol matures, and we start to see alternative node implementations, even that will erode as people deploy and run nodes that have custom prioritization rules for transactions.
The main problem here is that Cardano charges for used capacity, which grows linearly: an 8kB block uses 8kB, whether the chain is under load or not. But the resource that everyone is actually competing over is spare capacity, which becomes exponentially more valuable as it depletes. Using 8kB in a nearly empty block is very different from using the last 8kB in a block.
With Praos, we are bandwidth-limited, meaning there’s very little we can do to address this. It’s challenging to design a fair protocol that charges exponentially for that precious depleting resource, and it’s also challenging to increase that capacity dramatically.
dApps compete for that block space, and thus even with just a few dApps, user experience degrades dramatically when Cardano is under load. This is especially painful if the transactions are time-sensitive, like adding collateral to a loan before it’s liquidated.
This concern has been cited by some teams evaluating whether to build or deploy on Cardano, and in some cases has driven them away completely. It represents a huge potential barrier to the adoption goals we described in the previous section.
The value of Leios, as I hope to illustrate later, is not that it allows a single dApp to scale to thousands of transactions per second (that very few dApps need in practice), but that it provides the capacity for thousands of dApps to peacefully coexist, which is much more valuable for broad adoption of a blockchain.
By providing a scalable and elastic capacity to the network, Leios ensures that anyone can reasonably expect to get their transactions on-chain throughout a much wider range of chain conditions. Of course, there is still an upper bound, and we encounter similar problems at the extreme end, but those conditions are far less realistic to hit than our current upper bound.
Conclusion
In summary, if we do nothing, Cardano will begin struggling to pay for its own infrastructure as the tail emissions dwindle. There are many avenues to correcting this, all of which should be explored, but a critical one is to drive additional traffic. While not a substitute for actual business development initiatives, a key part of attracting that traffic is providing the capacity to meet it, and the conditions that provide for the best user experience possible.
This is just a high-level view of a problem with a dizzying number of variables and dimensions. You can dig more deeply into our analysis yourself, if you’d like, by reading this cost estimate summary, or playing with the numbers using the previously mentioned cost calculator.
Review of Ouroboros Praos
Overview of Ouroboros Praos
In order to understand Leios, it will be important to ensure we’re on the same page with regard to the basic operating principles, important properties, and key scaling limits, of the current network consensus protocol, Ouroboros Praos (or just Praos, for short).
When you submit a transaction, you submit it, either directly yourself or through some public API like blockfrost, to a Cardano node. This node validates that it is correct, inserts it into its own “mempool” (a list of transactions ready to be included in a block), and then shares it with each node it is connected to. Each of those nodes validates the transaction, inserts it into its mempool, and then propagates it downstream to their peers. Through this process, a transaction is “gossiped” around the network. In practice, a given transaction reaches nearly every node in just a few seconds. This means that, while you can’t assume this, in practice every stake pool node has a high degree of overlap in the transactions contained in their mempool.
Every second, each stake pool participates in a “slot lottery” to decide whether it is allowed to produce a new block. Conceptually, they combine some global entropy decided at the start of the current epoch, the slot number, and their VRF private key, to produce a verifiably random number. If that number is below a certain threshold, determined by the amount of stake they had at the start of the previous epoch, then the block they produce for that slot would be accepted by the network.
The threshold needed to produce a block is tuned, such that on average, one in every 20 slots, some stake pool on the network produces a block. Of the 3000 stake pools, roughly 1000 of them produce at least one block each epoch on average. This is referred to as a “Poisson Schedule” because the number of blocks produced in a given window of time follows a Poisson distribution.
The network parameters can be tuned in the following ways:
- More or fewer pools, on average, can be eligible each epoch (the so-called “k” factor)
- On average, there is a higher or lower fraction of slots that produce a block (meaning blocks are produced more frequently)
- The duration of a slot can be adjusted up or down
This process has the important property that nobody but the stake pool operator knows ahead of time when they will produce a block. This means that a clever attacker cannot time an attack on that node to bring it offline at the critical moment. Executing a denial of service on a single server is relatively easy and cheap while executing a denial of service on thousands of potential nodes is prohibitively expensive. So by keeping the block schedule secret, we prevent an attack where someone who wants to do Cardano harm can just direct their bot network to attack each node as their scheduled slot comes up: instead, they have to blanket a large portion of the network, all the time, to have any meaningful chance of appreciably delaying the network.
One of the ways that some other blockchains achieve such high speeds, and a big source of centralization risk, for example, is to have a public leader schedule: when you submit a transaction, you instead send it directly to the next several nodes that are scheduled to produce a block, optimistically assuming one of them will actually produce the block and include your transaction. However, this also means that it would be relatively cheap (on the scale of competitors or small nation-state actors) to consistently and continuously overwhelm those servers as their scheduled block came up.
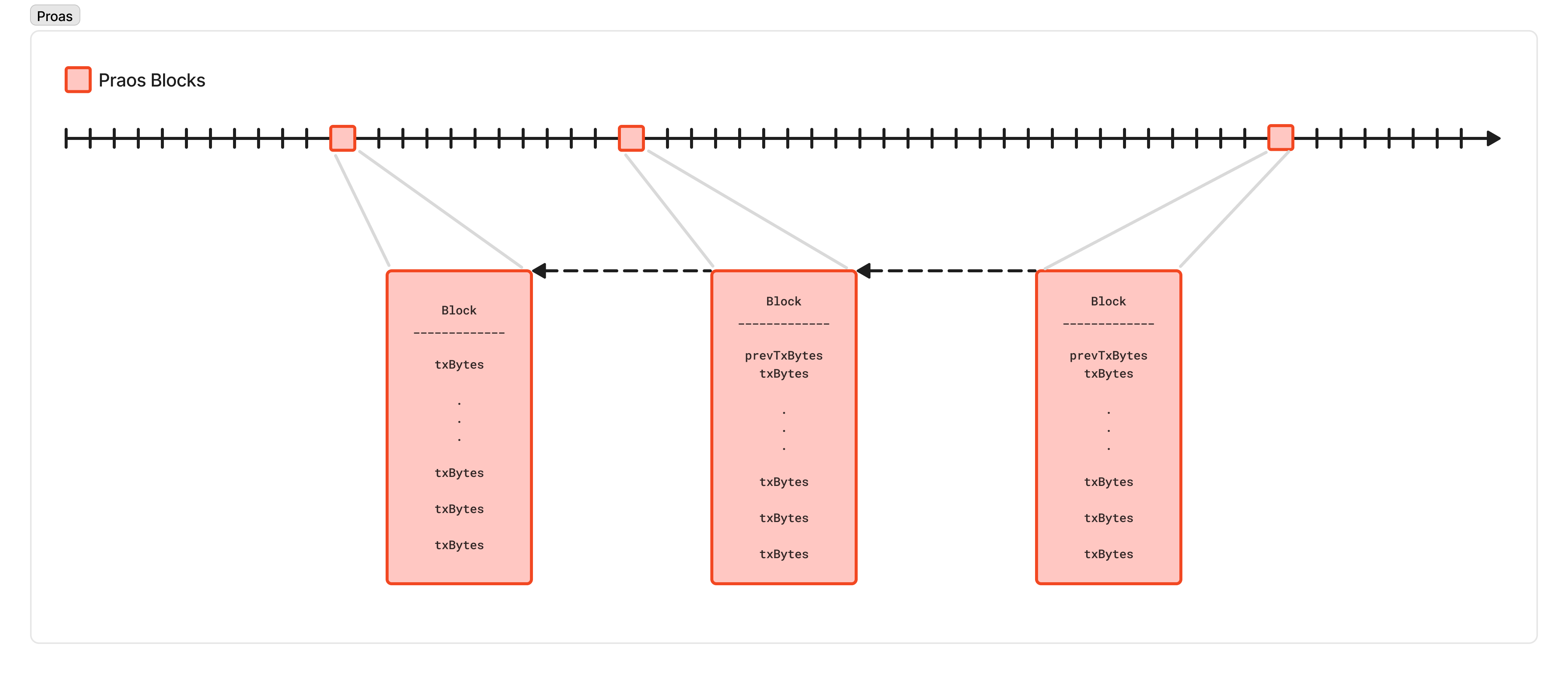
When a node is eligible to produce a block, it grabs as many transactions as it can (up to 88kB worth) from the mempool, produces a block, attaches the proof that they are eligible to produce that block, and begins to gossip that block to its peers in a very similar process to the transaction gossip protocol above.
However, because the schedule is private, and there’s no coordination among nodes to produce a block, there is also no way to prevent two or more nodes from being eligible to produce blocks in the same slot. This is known as a “slot battle” because two nodes are fighting to produce a block for the same slot.
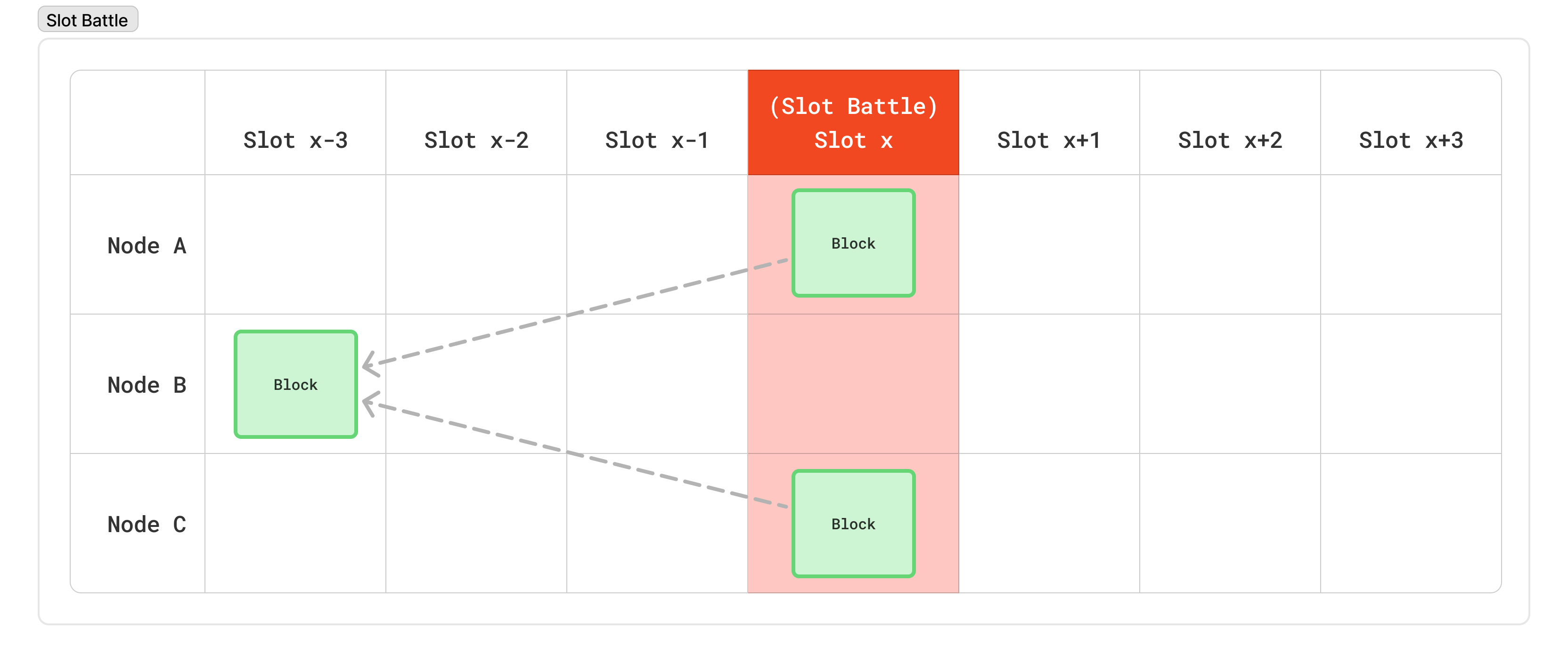
Similarly, because there’s no way to enforce a minimum time between blocks, two different nodes could be eligible to produce blocks back to back. In such cases, it is possible (even likely) that the second node won’t have heard about the previous block’s node. This will lead to two blocks at the same “height”. This is referred to as a “height” battle.
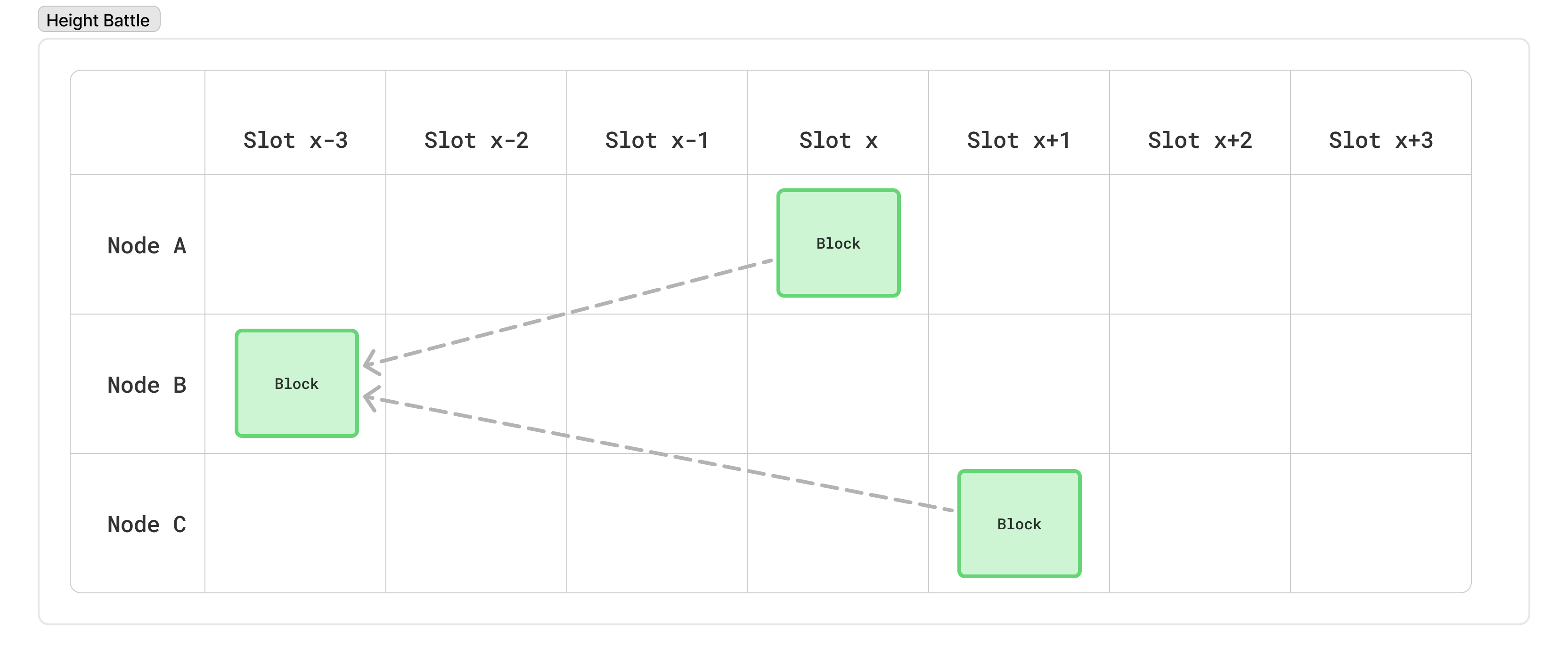
Finally, each of these can be relatively long-lived: there may be a wound in the network that prevents information from propagating efficiently, meaning several blocks could be produced by the time one part of the network learns about another “fork” that, itself, had several blocks produced.
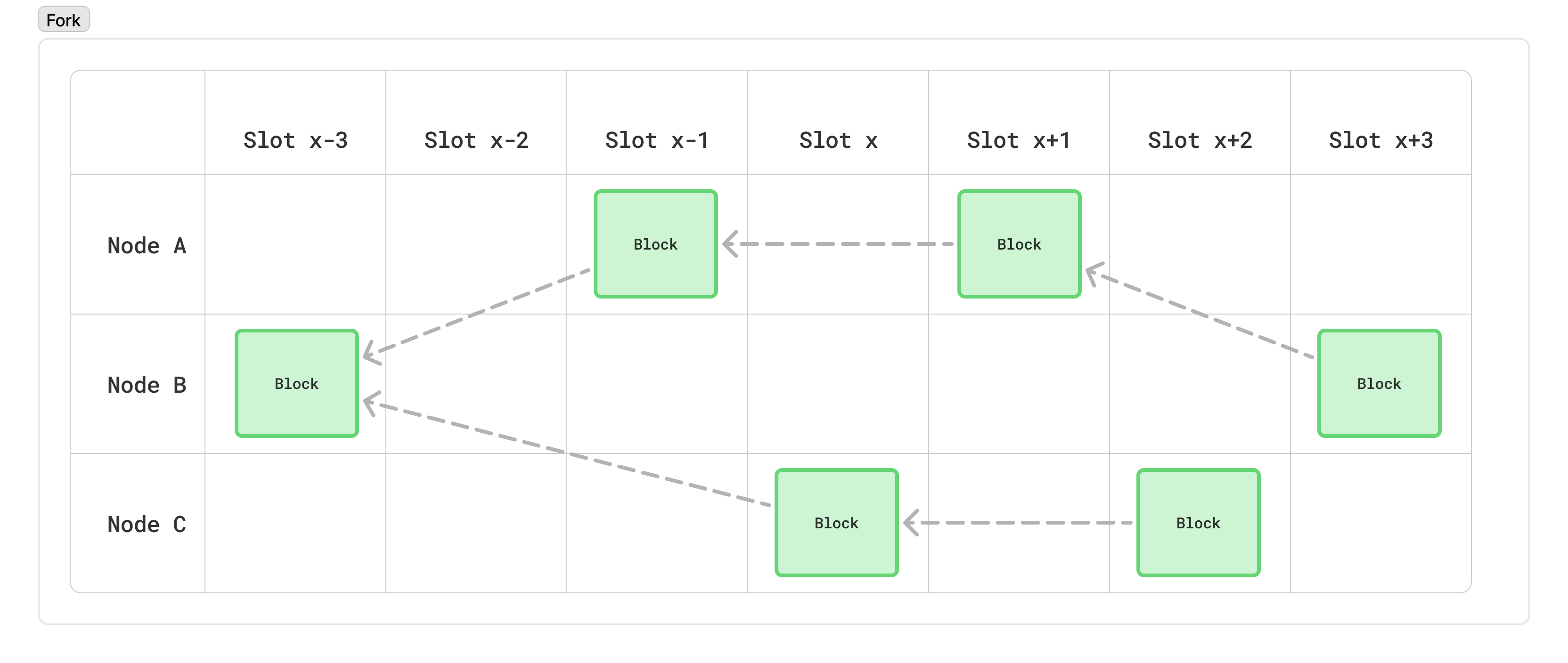
For all of these reasons, the network needs some kind of rule to decide which of these “forks” is valid. In Cardano, a node will always consider the “tip” of the network to be the longest chain of blocks it has seen. This is similar to Bitcoin’s longest-chain rule, so-called “Nakamoto consensus”. This rule ensures it is very difficult for an adversary with a small amount of ADA to create long alternate chains which cause confusion in the network, exactly because there is a low probability that they can create long chains in the first place.
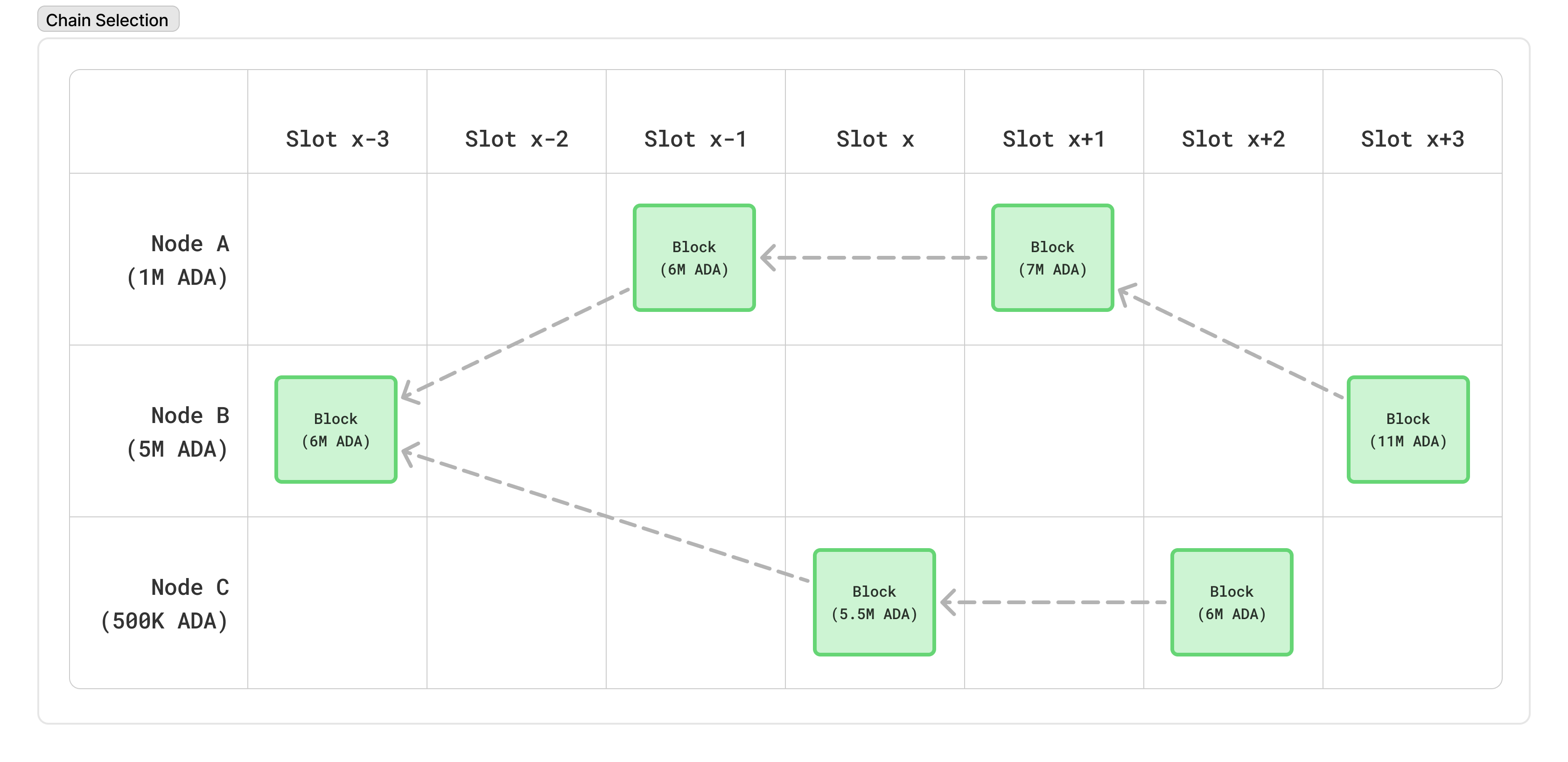
Note: In the above diagram, we assume that Node A and Node C are far enough apart that Node C hasn’t learned about Node A’s blocks by the time it produces its own
The final rule, however, is that a node will never switch to another fork whose common ancestor to the current fork is over 2160 blocks in the past. This is referred to as the “rollback horizon”, and ensures that any block that is at least 2160 blocks old is considered permanent, and prevents an attacker from producing a very long chain in private and revealing it only very late in the game.
All-together, this consensus protocol ensures 2 important properties:
- Everyone converges on the same chain
- The chain continues to grow with honest blocks
Thinking with Light Cones
One framing that will be useful as we study Ouroboros Leios is to think of events in terms of the communication “light cones” on the network. This leans on an analogy to relativistic physics, and is a way to think about the “local view” of a node: all the past events that it can know about, all the future events it can possibly influence, and anything happening “concurrently” that it can do neither.
Consider the diagram below:
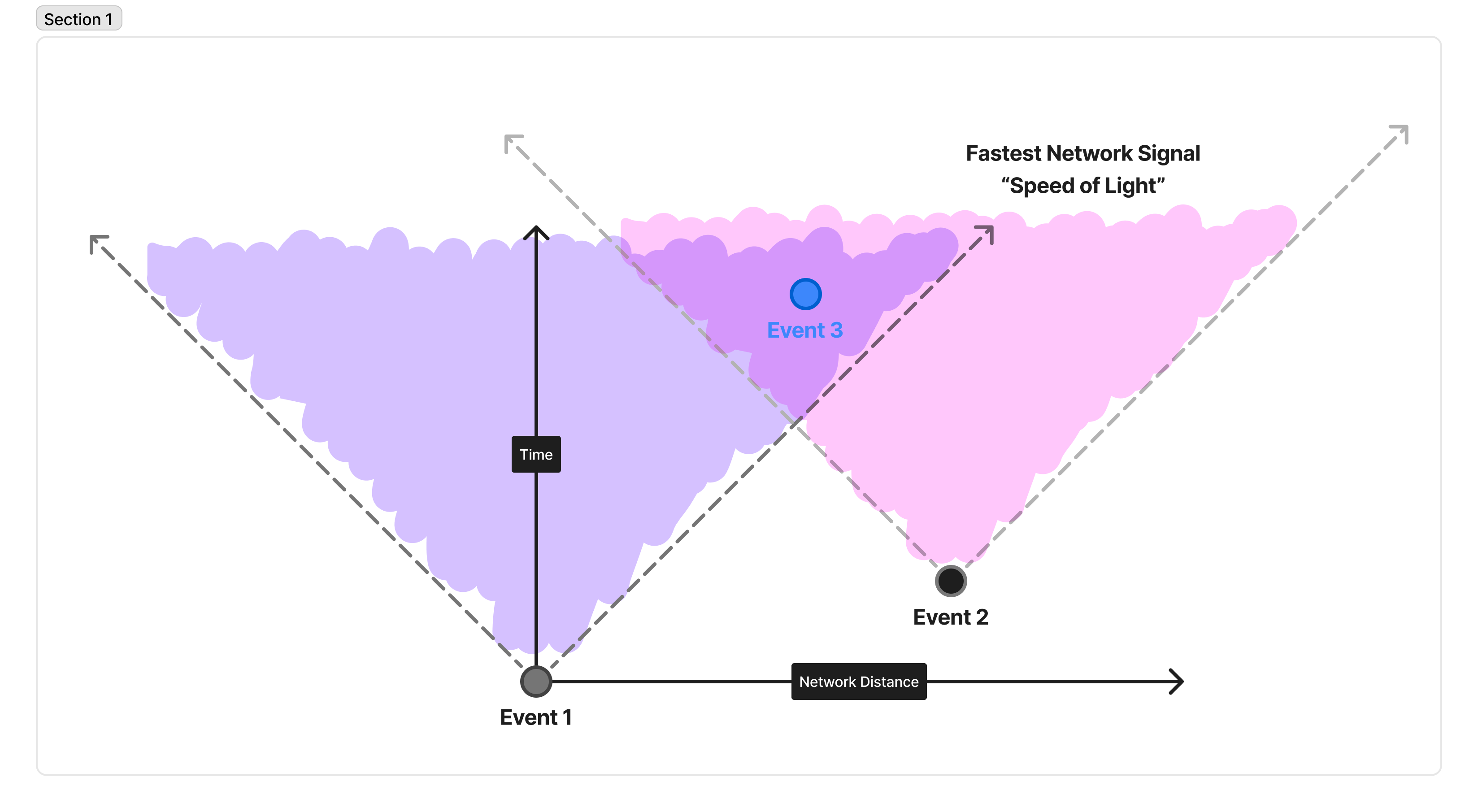
In this diagram, discrete events are represented as circles. They’re separated vertically in time, and horizontally in space. In our case, for example, Event 1 happens, and then Event 2, and then Event 3, because you read from bottom to top. However, Event 2 happened very close to Event 1, and Event 3 happened further away. Here, we don’t mean physical distance, but instead are talking about how fast a network packet could travel from one to the other.
There is fundamentally a maximum speed a message can propagate across the network, represented by the 45-degree angle line. The region inside these two lines is called the “light cone” because it is the cone of all points in space and time that light (a “message” in our example) sent by one event could reach another in time. So, in this example, it is feasible for a message sent by Event 1 to reach Event 3 by the time it happens. Likewise, Event 2 has its own “light cone”, and it’s possible for a message sent by Event 2 to reach Event 3 by the time it happens. However, it is not physically possible for a message sent by Event 1 to reach Event 2 before it happens!
This is why height battles occur: in one second, a node produces a block, but there’s not enough time for that block to reach the next node scheduled to produce a block. Thus, that other node can’t be influenced in any way by the first block, and so they will necessarily fork the chain.
Key scaling limits
So, if we want to scale Praos, what is preventing us from shortening the slot length to 100 milliseconds? Or raising the block density, so we produce blocks every 5 seconds instead of every 20 seconds? Or increasing the maximum size of blocks to 10 megabytes?
Fundamentally, Praos is limited by bandwidth. While short-lived forks are possible (and rather frequent) in Praos, the parameters are selected to ensure that those forks are indeed short-lived. With an average of 20 seconds between blocks, there is plenty of time for each block to propagate across the network and settle disputes about what the canonical tip is.
If you increase the block density significantly, then far more nodes will produce blocks in the same slot, and slot battles will become more frequent.
If you shorten the slot length, then there is much less time between when nodes produce a block. Because of this, height battles become far more frequent.
If you increase the maximum block size, then it takes longer to download the block to be ready to produce the next one, and again, height battles become far more frequent.
The security of the chain degrades as forks become more frequent: with a higher number of forks, you need to increase the rollback horizon to ensure everyone converges on the same chain, meaning transaction finality suffers. Additionally, the honesty guarantees of the chain worsen, and you can have longer stretches between honest blocks, meaning an attacker can start to pick and choose the transactions they include, which can be used to bias the stake distribution in their favor (by, for example, refusing to include any transactions which delegate away from them), or bias the entropy selected for next epoch so they get an abnormally large number of blocks, et cetera.
This security degradation is not linear; It is challenging to say “Well, we set those parameters very conservatively, so maybe it’s ok to accept a 20% reduction in security for 20% more frequent blocks”. Instead, even small reductions in this margin lead to exponentially worse security properties for the chain over long periods of time.
We can see how changing these parameters increases the number of forks fairly intuitively if we look at the light cone behavior of producing a block. Here is the standard, happy path of blocks being produced on Cardano, depicted as a light cone diagram.
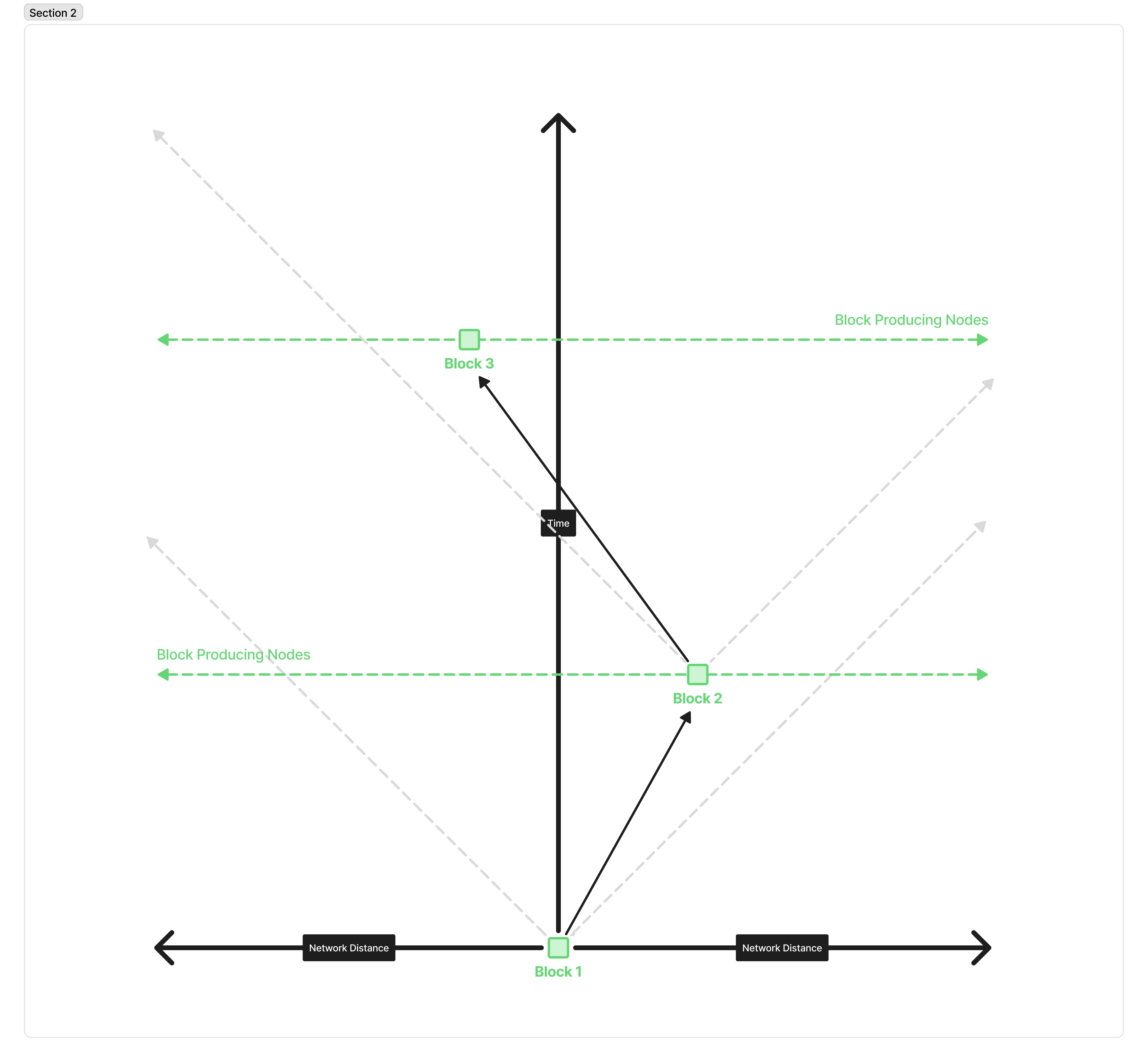
This depicts 3 consecutive blocks being produced, with no slot or height battles. The grey lines represent the fastest the block could travel across the network. The arrows represent (some of the) messages traveling through the network; the circles represent blocks being produced; and the green lines represent all of the various block-producing nodes on the network.
Block one is produced and propagated across the network. Because there’s a decent gap between Block 1 and Block 2, it has plenty of time to reach any node in the network that might happen to produce the next block. The same is true from that new node propagating its block across the network within its own “light cone”.
But, if we compress the time between blocks heavily, the picture starts to look like this:
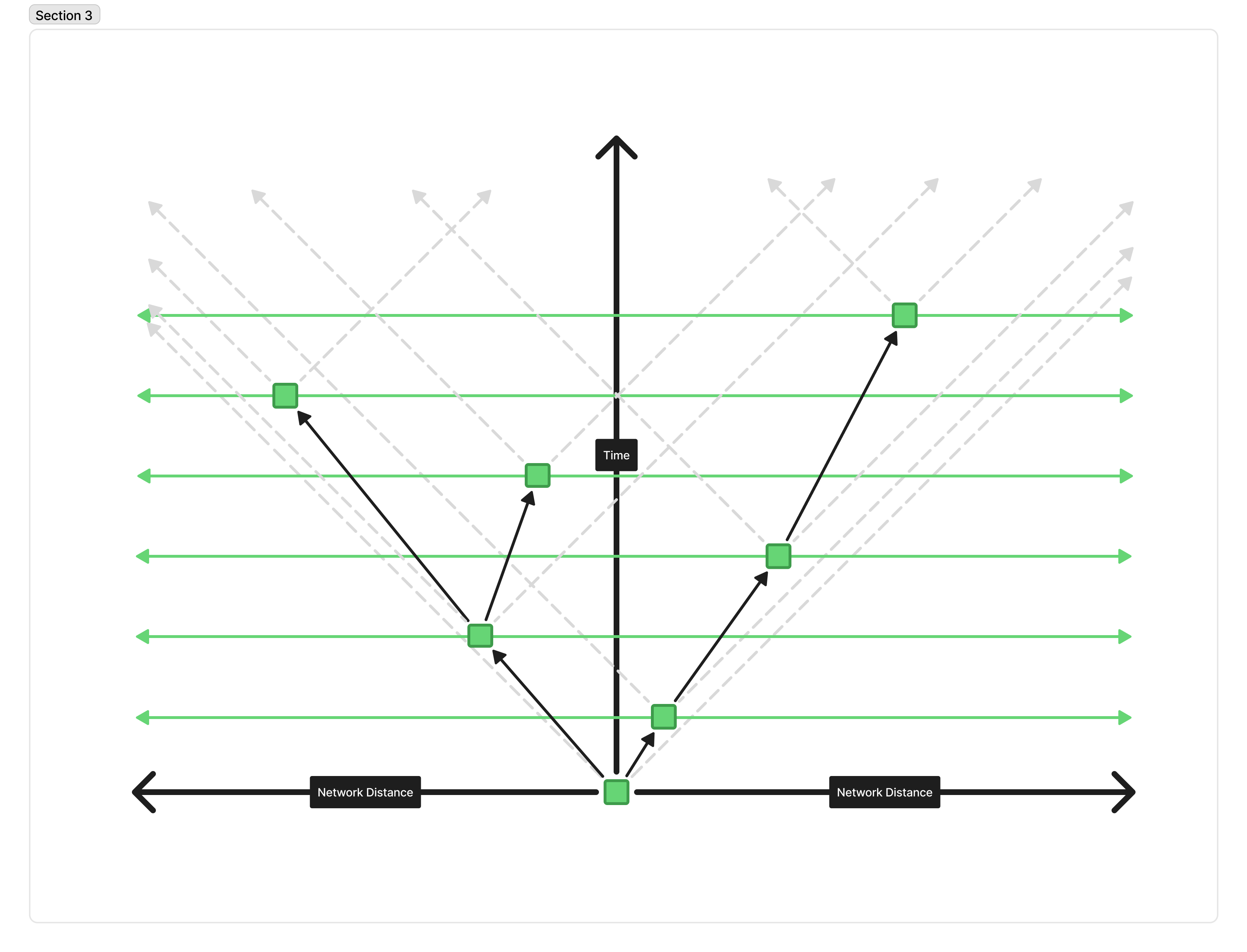
We can see that forks immediately become much more frequent because there is often not enough time for a block to propagate to the next peer that will produce a block.
Similarly, if we make blocks bigger, it takes longer to download these blocks, meaning messages propagate across the network slower, effectively “narrowing” our light cone, and a similar picture emerges:
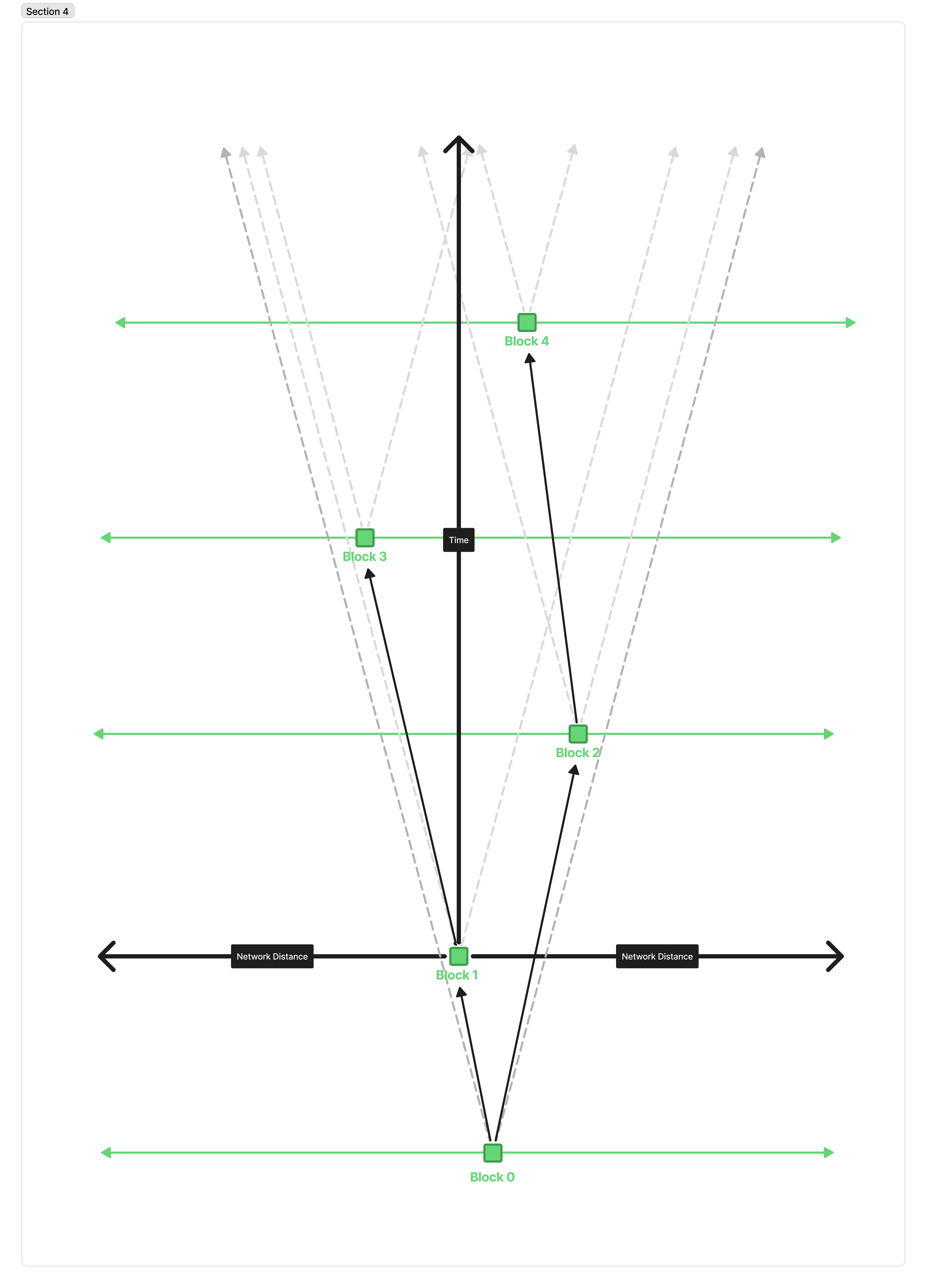
Forks emerge because even though a smaller message could have reached the next node in time, alerting them that it exists, they won’t be able to finish downloading the block, so they can’t validate it to produce the new block on top of it.
So the key takeaway is that Praos relies on a relative “quiet” period between blocks, to ensure that blocks have plenty of time to saturate across the network before the next block gets produced. This quiet period means that there is a fundamental tension between the security and throughput of the network. The throughput of the network is constrained by the worst-case scenario of two blocks being separated by a single second, but the average case only has to process blocks every 20 seconds or longer. In practice, a node spends less than 1% of its time doing useful work!
Two key questions led to the invention of Leios. I leave them here, in case the clever reader wants to ponder on them on their own before reading on to how Ouroboros Leios solves this:
- What if we could produce blocks in parallel, and only sequence them later?
- What if we didn’t have to download the blocks at all to decide on a sequence?
Building up to Leios
Now, rather than explaining Leios immediately, I’ve found it’s most helpful to build up to Leios with a sequence of protocols, each of which naively attempts to try to address a problem with the previous one. Then, we will show how that protocol is vulnerable to some kind of attack. If you’d prefer to just read a complete description of Leios, rather than following how you might arrive at that design yourself, feel free to skip to the next section! You can come back later if or when you get curious about why certain decisions were made.
Leios 0 - Design
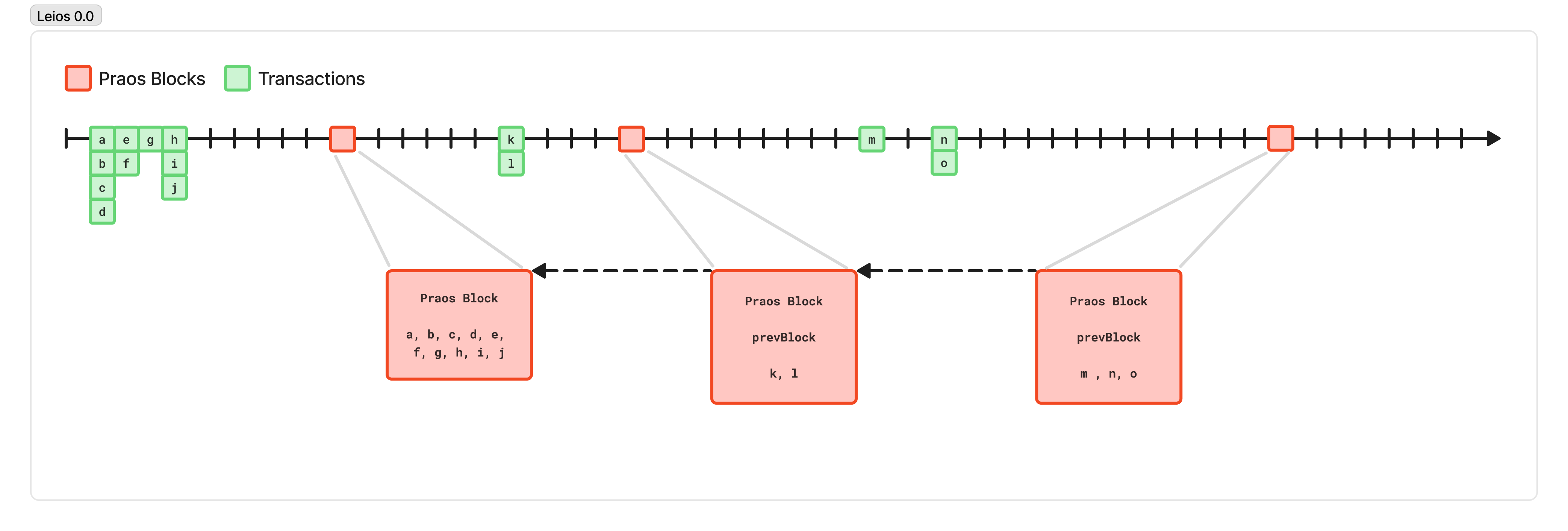
To understand the first step we’ll take, let’s look at that first phase of the protocol a bit closer, where we propagate transactions through the network to fill up the mempools.
While propagating transactions in the mempool, there’s no requirement that we “wait” for a previous block. This means we can effectively utilize bandwidth because transactions are relatively small and can be propagated at any time, meaning they can fill in periods of silence to fully saturate the connections between two nodes. This means that the maximum throughput of propagating transactions, so long as we’re not trying to reach consensus and sequence them into blocks, is tremendous.
A decent lower-bound estimate on the average bandwidth available between high-quality network nodes is 100 megabits per second. If we take a pessimistic view, and half that to 50 Mbps, and assume our average transaction is 350 bytes, then we can propagate around 17850 transactions per second!
And, let’s observe that we’re effectively downloading each block twice: First, we download the individual pieces of some future block by downloading the transactions as they are propagated across the network before they are included in a block; and then when a block is produced, the block is composed of individual pieces we’ve very likely downloaded before!
So, let’s change the format of our blocks: instead of a block containing the full bytes of each transaction, a block just consists of the transaction hashes it includes. Now, using the same Praos protocol, which produces a block up to 88 kilobytes large every 20 seconds on average, we can reference ~2750 transactions, for a throughput of 137.5 transactions per second. And, since we have (likely) already downloaded and validated those transactions to include them in our mempool, we have to do less work to validate the block. We can likely make the blocks bigger and more frequent, relying on most of the work to happen in real-time, while we download the transactions, rather than right when we must produce the block.
Now, instead of a node that hits 95% CPU each time a block is made, but is quiet the rest of the time, we can fully utilize our resources and consistently do useful work at all times.
Leios 0 - The Attack
Unfortunately, the key weakness in the protocol above is the word “likely”.
If you download a block from a peer, and you haven’t seen one of the transactions it references, you have to wait until you do. Perhaps you can request that from a peer, but then in the worst case, we just revert back to downloading the transactions after we’ve been told about the block, which is equivalent to if they had just been included in the block in the first place, which destroys our security guarantees.
Worse, suppose a malicious block producer includes references to transactions that no one has seen! They could generate 32 random bytes, claim that was a transaction that had been propagated to them, and share a block containing this “transaction ID” throughout the network, halting the production of every other node while they tried to download a transaction that didn’t even exist!
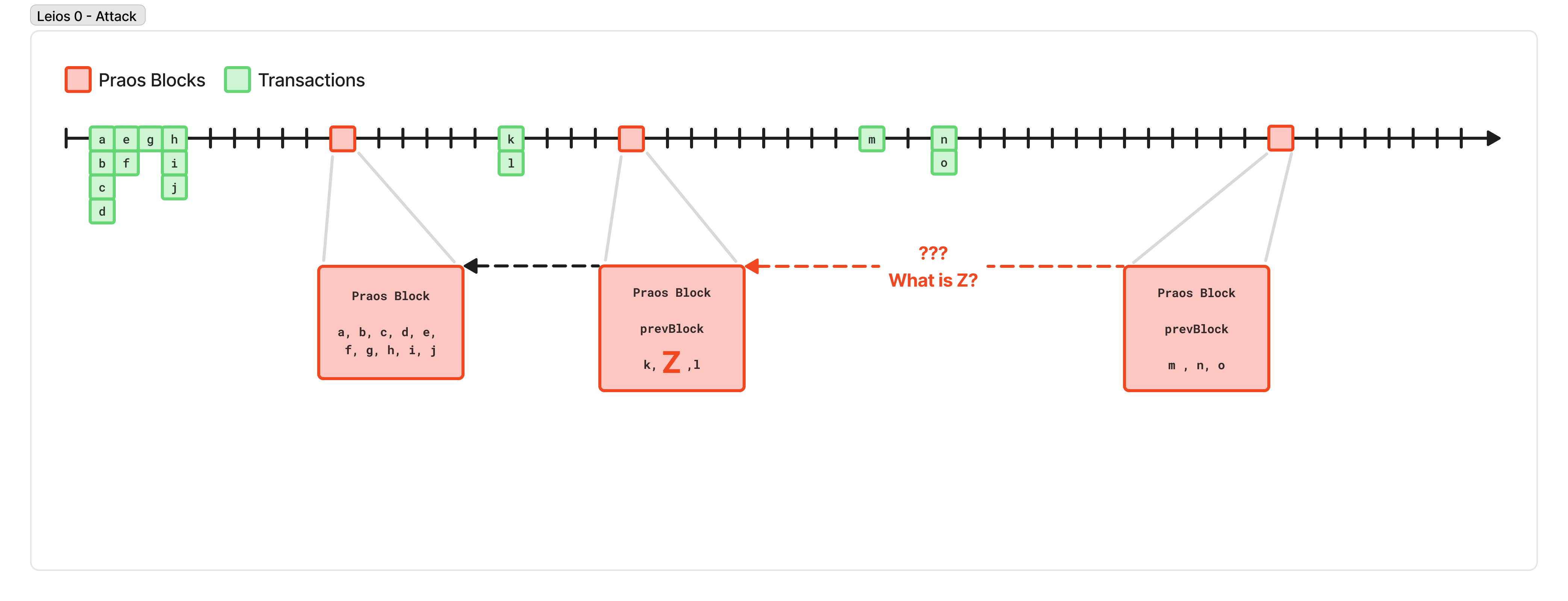
This is a data-availability problem: when downloading and validating a block from a peer, and deciding which fork is the current tip, a block-producing node needs some way to have high confidence that even if they haven’t seen and validated a specific transaction yet, they will see the transaction soon, and it will be valid.
Leios 0.1 - Design
To fix this, we can borrow an idea from a related Cardano project called Mithril.
In Mithril, stakepool operators opt in to “vote” on certain payloads, such as a checkpoint of the ledger state. Their vote carries a certain weight, depending on their stake. Thus, building on the assumption that a majority of the stake in the network is honest, once a certain majority of the stake of the network has voted on a specific payload, you can safely rely on the integrity of that payload.
Cardano projects like cardano-up by Blink Labs, or dolos by TxPipe use this property to quickly bootstrap a Cardano node without having to synchronize and validate the whole history of the blockchain from scratch.
In Leios 0.1, we’re going to allow stake pool operators to “vote” on transactions that are available and valid. We gossip these votes throughout the network, and each node gathers votes until it’s seen at least 70% of the network vote on the transaction. Then, when we produce the Praos block, we include only the transaction IDs of any transactions that have reached the threshold, and a compact “certificate” proving we’ve seen a sufficient number of votes, using something like ALBA Arguments.
Now, when we receive the block, we just check the certificate for the transactions we haven’t yet seen, and we can have very high confidence that the whole block will be available and valid before we’ve downloaded every piece of it. This allows our blocks to be small, propagate quickly, and include lots of transactions that were produced in parallel.
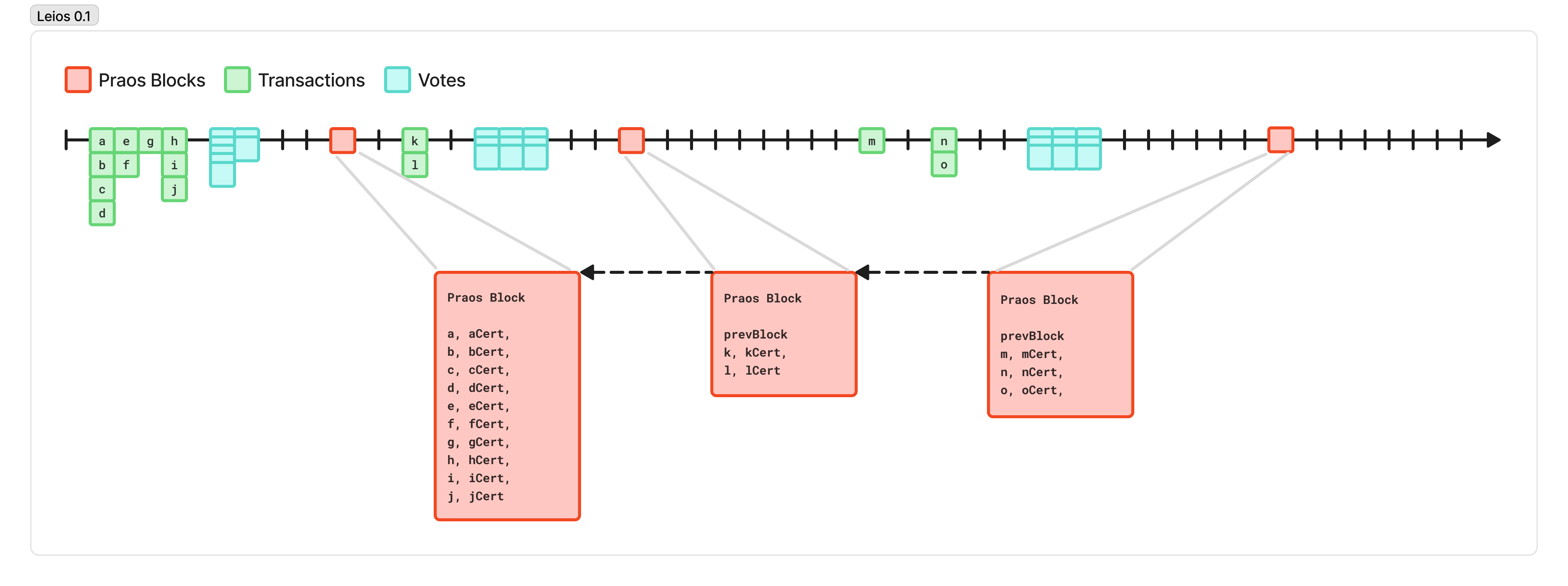
Leios 0.1 - The Flaw
If I was narrating this blog post, it’s at this point that I would insert a record scratch.
Unfortunately, the design above performs even worse than Praos! What went wrong?
In practice, this process of voting on transactions is very slow (we need to propagate votes from hundreds of stake pools to reach the required threshold), and the certificates are very large (several kilobytes). Suddenly, we can only fit a few transactions in a block, most of our network traffic is eaten up by propagating millions of these voting messages, and the time it takes for any given transaction to make it into a block is on the order of several minutes, if not longer!
Clearly, “transactions” is not the right level of granularity for making these attestations and certificates.
Leios 0.2 - Design
If transactions are not the right granularity for these certificates, let’s instead group transactions into large batches. We’ll gather dozens or even hundreds of transactions, and propagate them around the network as a group. The block producers will cast “votes” on these blocks, sharing those votes with their peers.
We can also produce these batches in parallel around the network, to better utilize our bandwidth.
Like before, once any node observes votes from a majority of the stake, they can produce a compact certificate. Then, when a node becomes eligible to produce a Praos block, they can include a reference to that batch, and the certificate proving its availability and validity.
To differentiate between these two different groupings, we introduce the following names for them:
- Input Blocks: large batches of transactions, that represent the input to the system
- Ranking Blocks: blocks produced via the Praos consensus protocol, which determine some ordering for transactions
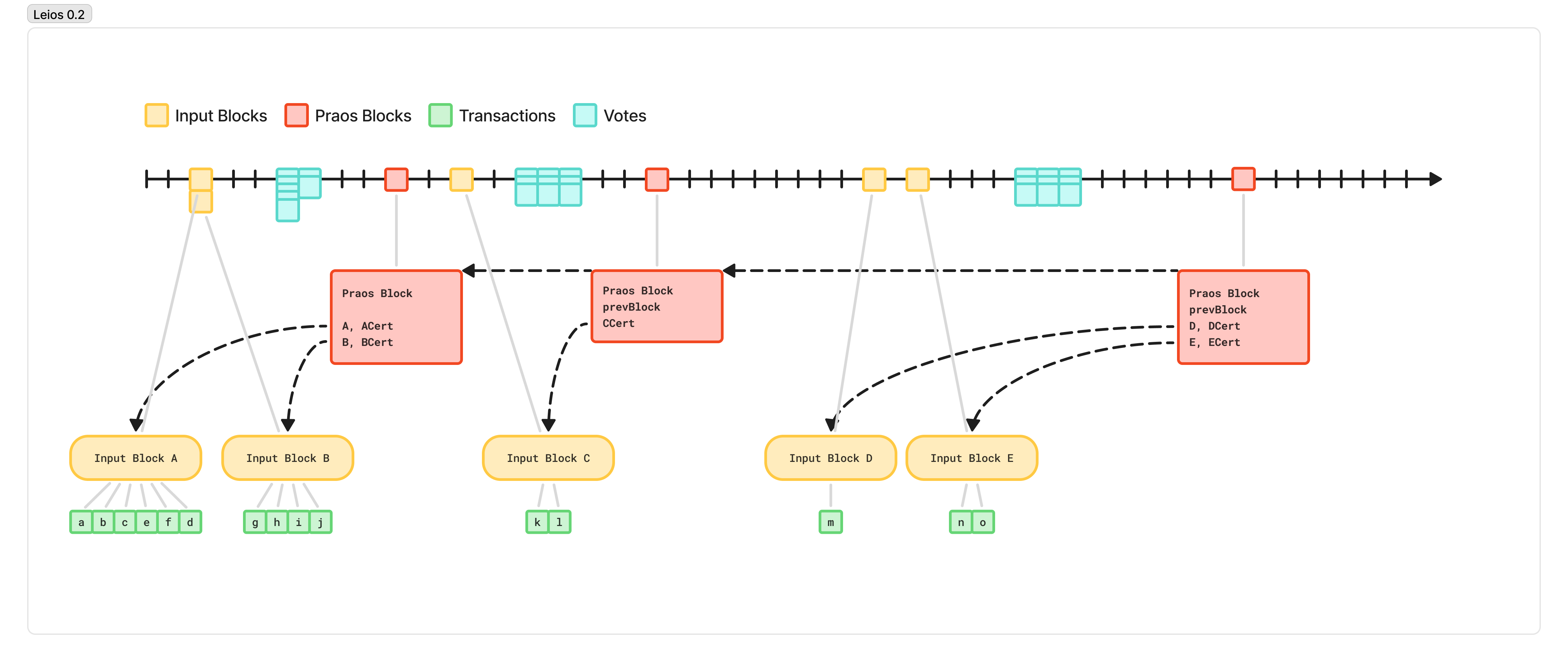
Leios 0.2 - The Shortcoming
Unfortunately, this only gets us so far. If we try to make these input blocks too big, then we have ruined the concurrency properties that let us saturate the bandwidth of the network. And if we try to produce too many in parallel, then only a few will make it into the Ranking blocks because of the size of the certificates.
We would like to produce input blocks that are at the right granularity for parallelized generation, such that we don’t lose all of our efficiency to scheduling overhead, while also reducing the overhead introduced by voting and including a certificate.
It’s only half tongue-in-cheek that I say: this is computer science, so the problem is solved by adding another layer!
Leios 0.3 - Design
To address the above, we introduce yet another type of block, specifically for this “endorsement” and voting stage. We call these, unimaginatively, Endorsement Blocks.
Now, the protocol generates mid-sized “input blocks” that aggregate many transactions. These are large enough to represent a meaningful amount of work for a single core to validate so that when we validate them in parallel, the scheduling overhead lost to multithreading is minimal, but small enough that they can be generated concurrently across the whole network, and efficiently saturate the network bandwidth between nodes. This is a parameter that can be tuned, but you can think in the 100 kilobytes to 350 kilobytes range, representing several hundred average-sized transactions.
These are produced at a high enough rate to saturate most of the network bandwidth, and concurrently across the whole network. Again, this is a parameter that can be tuned, but just to build a mental model, you can picture the network producing 5 input blocks per second.
To ensure these blocks are produced at a useful rate, and resistant to censorship, we use a similar “Poisson Schedule” slot lottery as in Praos, but at a much higher frequency.
Then, using another, separate slot lottery, nodes on the network are also eligible to produce endorsement blocks. These aggregate the IDs of all the input blocks seen by that node and attest to the validity and availability of the nodes. As this block is propagated around the network, other nodes validate that, yes indeed, these transactions exist and are valid, and vote with their stake weight on that validity.
Endorsement blocks in this design are produced roughly as frequently as Ranking blocks.
Like in previous designs, once an Endorsement block reaches a supermajority threshold of stake votes, then the next time a Ranking block is produced, the slot leader includes the single endorsement block and the single compact voting certificate. Because this block now canonically decides the ordering, when other nodes download this block, they can validate the certificate and have high confidence that, even if they haven’t downloaded all the transactions yet, they will soon, and they will be valid with high probability. That confidence means that, when it comes time to produce the next ranking block, even if it’s just a short time later, they can do so, even if they haven’t yet reconstructed the full ledger state. This, ultimately, keeps network forks very low and maintains all of the great properties of Praos.
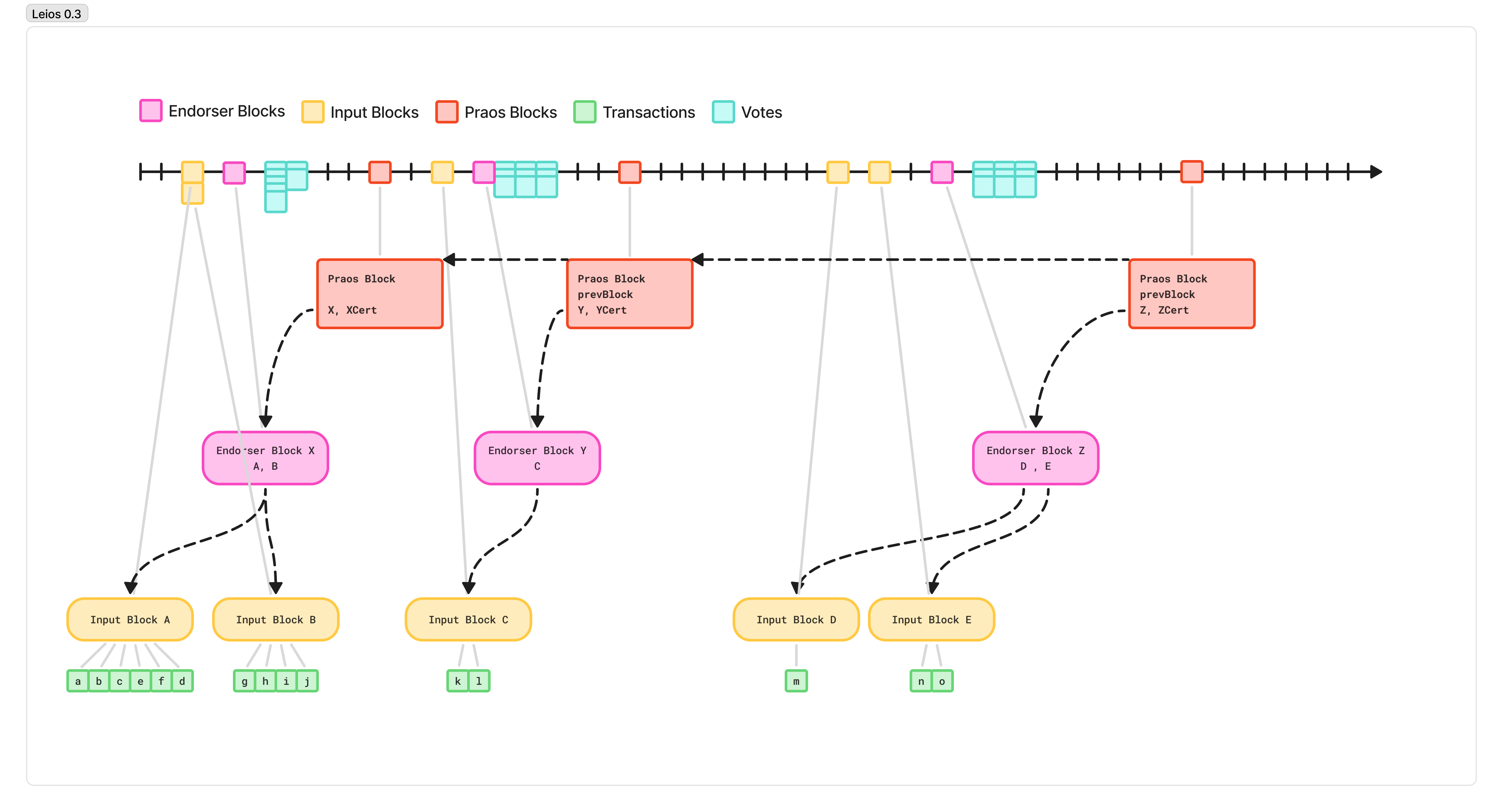
Leios 0.3 - Suboptimality
The design described above is very close to the full Leios protocol, but it still ultimately under-utilizes the network. The network needs to have enough time to propagate input blocks, include them in an endorsement block, circulate votes on endorsement blocks, and finally include the certificate in a Ranking block. Given the extra delay, the time between ranking blocks has stretched from an average of 20 seconds, up to 75 to 150 seconds.
We’ve replaced one “quiet period” with another.
Leios 0.4 - Design
Building on the previous protocol, we can increase the density by copy-pasting the protocol with a technique known as “pipelining”.
We can run multiple instances of the protocol described above in parallel but shifted in time. At any given point in time, there is one copy of the protocol that is generating input blocks, another copy that is generating endorsement blocks, another that is voting on that endorsement block, and another that is producing a ranking block.
In this way, we restore the regular, 20-second heartbeat of Ranking blocks, each packed with the full networking capacity that the network of Cardano nodes can support.
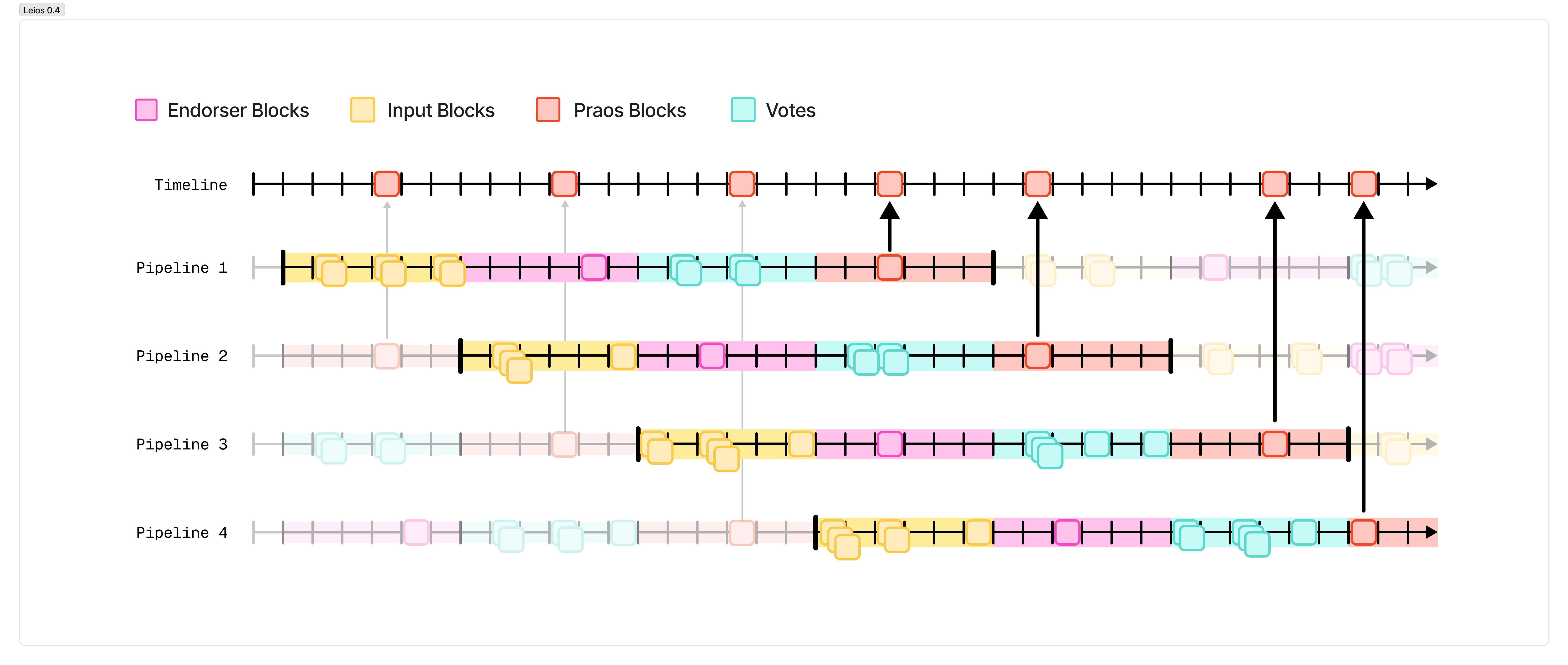
Leios 0.4 - Chain Quality
There’s one final problem in the design above (at least, one final problem that we have a clear solution for), and one final improvement to the protocol I’d like to present before we arrive at the version of Leios described in the research paper.
The main remaining problem has to do with chain quality. Chain quality is a property described in the original Ouroboros Praos paper, and it represents the number of honest blocks within a given window of time. A high chain quality means that there are relatively short windows of time between any two honest blocks, while a lower chain quality means that those windows of time starts to grow. Chain quality drops, for example, when someone fails to produce a scheduled block, or produces a block that maliciously censors transactions, for example. The Ouroboros Praos protocol places bounds and guarantees on the chain quality of the network.
However, when chain quality drops in Ouroboros Leios, it has an outsized impact. If a ranking block isn’t produced for a specific pipeline, then the endorsement block from that pipeline never makes it on-chain, and all of the transactions it references are lost. Similarly, when a malicious stake pool operator is elected to produce a block they can choose an endorsement block that censors transactions they don’t like, or refuse to select an endorsement block at all.
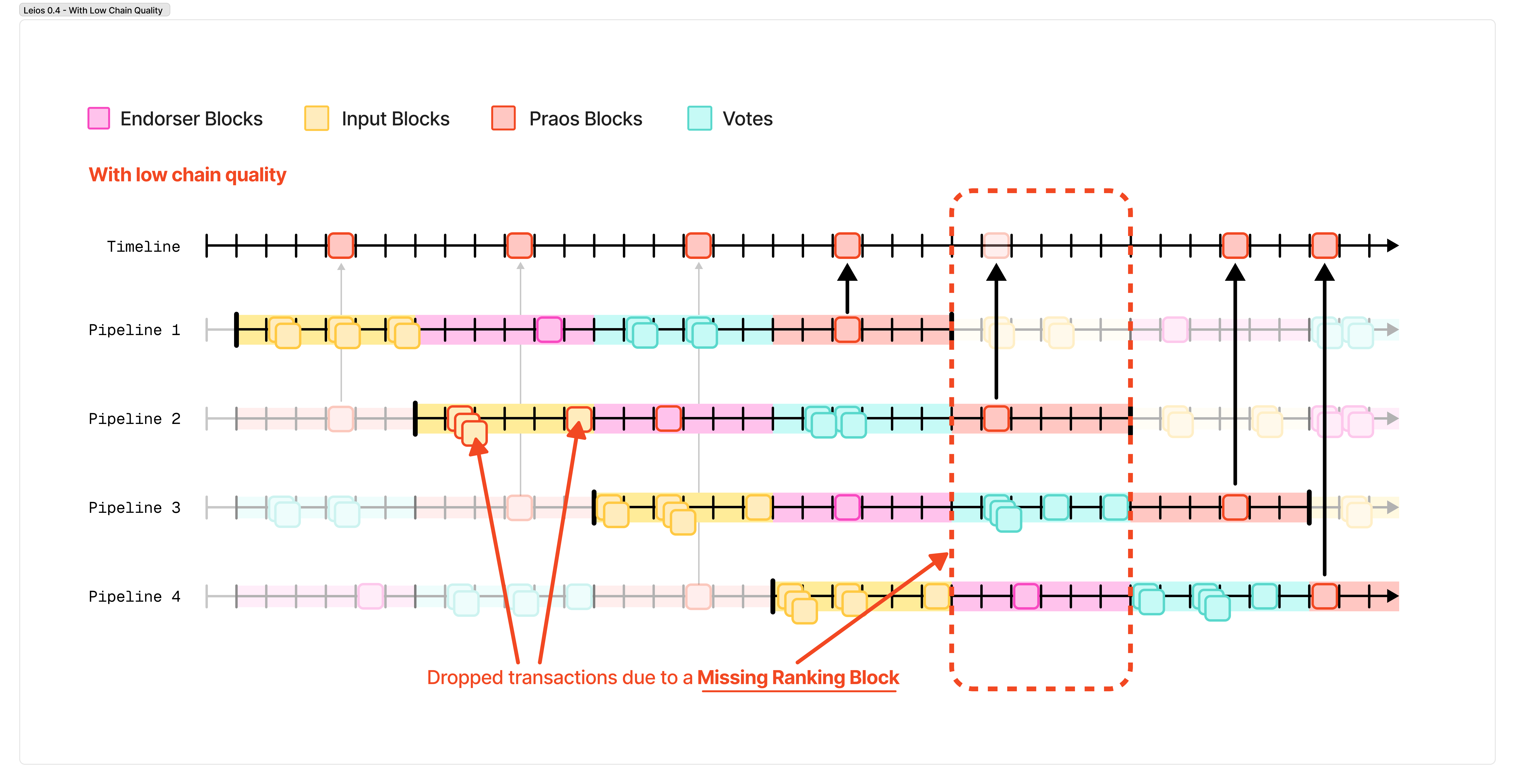
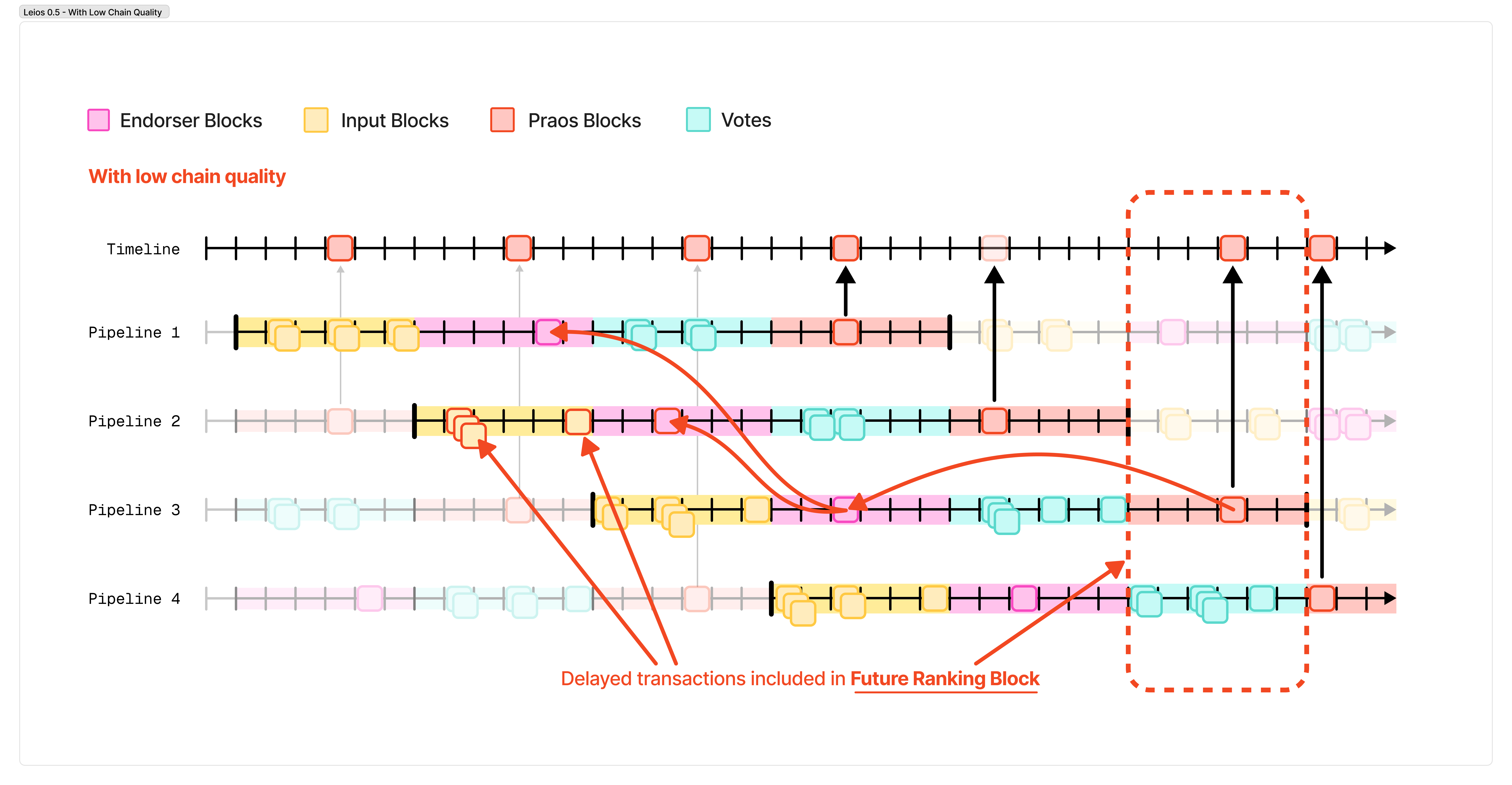
Leios 0.5
To resolve this is fairly simple: endorsement blocks are allowed to reference previous endorsement blocks, in case they were missed.
When reconstructing the sequence of transactions afterward, we first follow these recursive references to find any endorsement blocks that haven’t yet been seen on-chain.
This ensures that, if we miss a ranking block, the bounds on chain quality that Ouroboros Praos gives us will ensure that the missed endorsement block is eventually included.
Ouroboros Leios
To recap, or if you skipped the last section, here is a concise description of the Leios protocol, as we understand it so far:
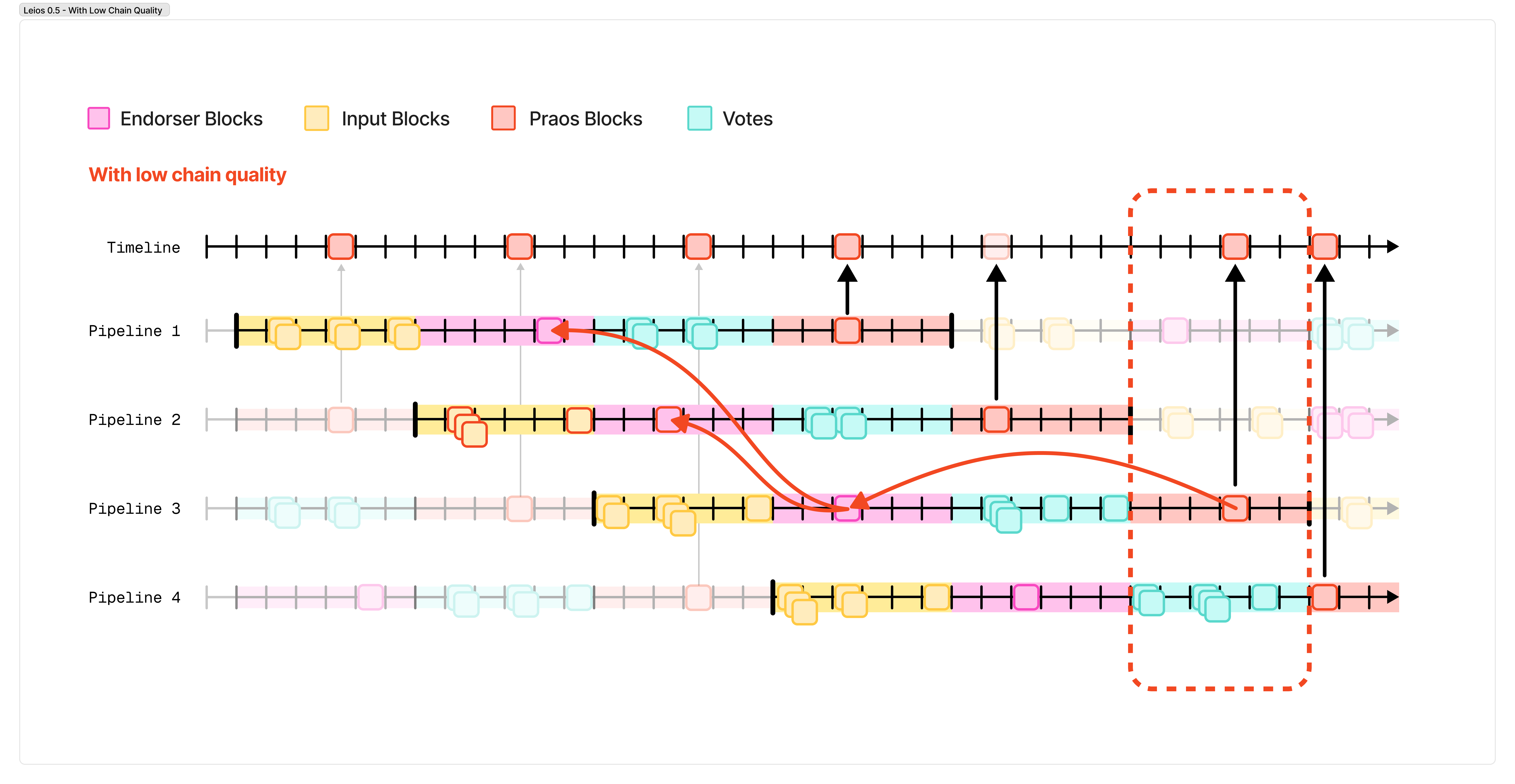
Leios runs as a “pipelined” protocol, where the same protocol is run multiple times currently, shifted relative to each other in time. You can picture this as when a chorus sings in “rounds”.
A single pipeline is divided into several stages, each of which lasts a number of slots. The next pipeline begins after the previous one finishes its first stage.
In the first stage, nodes across the network generate high frequency (1-5 per second) fairly large (~100-300 kilobyte) “Input Blocks” each of which contains user transactions, and diffuses them throughout the network.
In the second stage, nodes produce an “Endorsement Block”, which references a set of input blocks that are valid with reference to some recent ledger state. These endorsement blocks are diffused throughout the network. The “Endorsement Block” also references other, recent endorsement blocks from past pipelines.
In the third stage, as nodes observe a new endorsement block and validate it themselves, they sign a “vote” for the endorsement block and diffuse those votes throughout the network.
In the final stage, as nodes get elected to produce a normal Praos block (now called a “Ranking Block”), they select an endorsement block that has received votes from 70% of the active stake, and produce a compact certificate proving the endorsement block is reliable, and include that in the Ranking Block.
This is a mostly faithful description of the version of Leios described in the research paper. There are some other small devils in the details, such as the timing on these different phases, how long an input block is valid, etc., and some changes that the Leios team is exploring as part of their R&D efforts, but I’ll refer to you to the specification or our simulation work for these specifics instead of bloating this already fairly lengthy blog post.
Leios Performance and tradeoffs
For the last 6 months, Input Output, along with support from Well-Typed and Sundae Labs, has been studying the real-world behavior of the protocol described above. It’s all well and good to have a research paper in hand that describes the soundness of a protocol; it’s another thing entirely to understand how different choices of protocol parameters impact the real-world performance, and what range of real-world performance and cost such a protocol is likely to be able to achieve.
At the same time, many of these improvements come with tradeoffs, albeit reasonable ones. These tradeoffs can be thought of as currency that the current Cardano protocol has worked hard to accumulate, that we now get to spend on increasing our assets. Understanding these tradeoffs will be key to the successful deployment of the Cardano network.
In the next few sections, I will summarize the main takeaways from that effort, though keep in mind the topic is heavily nuanced even still, and none of this should yet be construed as an absolute promise of the protocol’s capabilities.
Throughput
The main variables impacting throughput are the frequency of input blocks and their size. Below is a chart depicting how these impact the overall, steady-state maximum throughput of the protocol, with reference to a “typical” transaction, averaged over all normal, Plutus v2, or Plutus v3 mainnet transactions from epoch 500 to 550. (Note: we exclude Plutus v1 transactions because, even with CIP-110 which enabled reference scripts, they significantly skew the average size of the transaction).
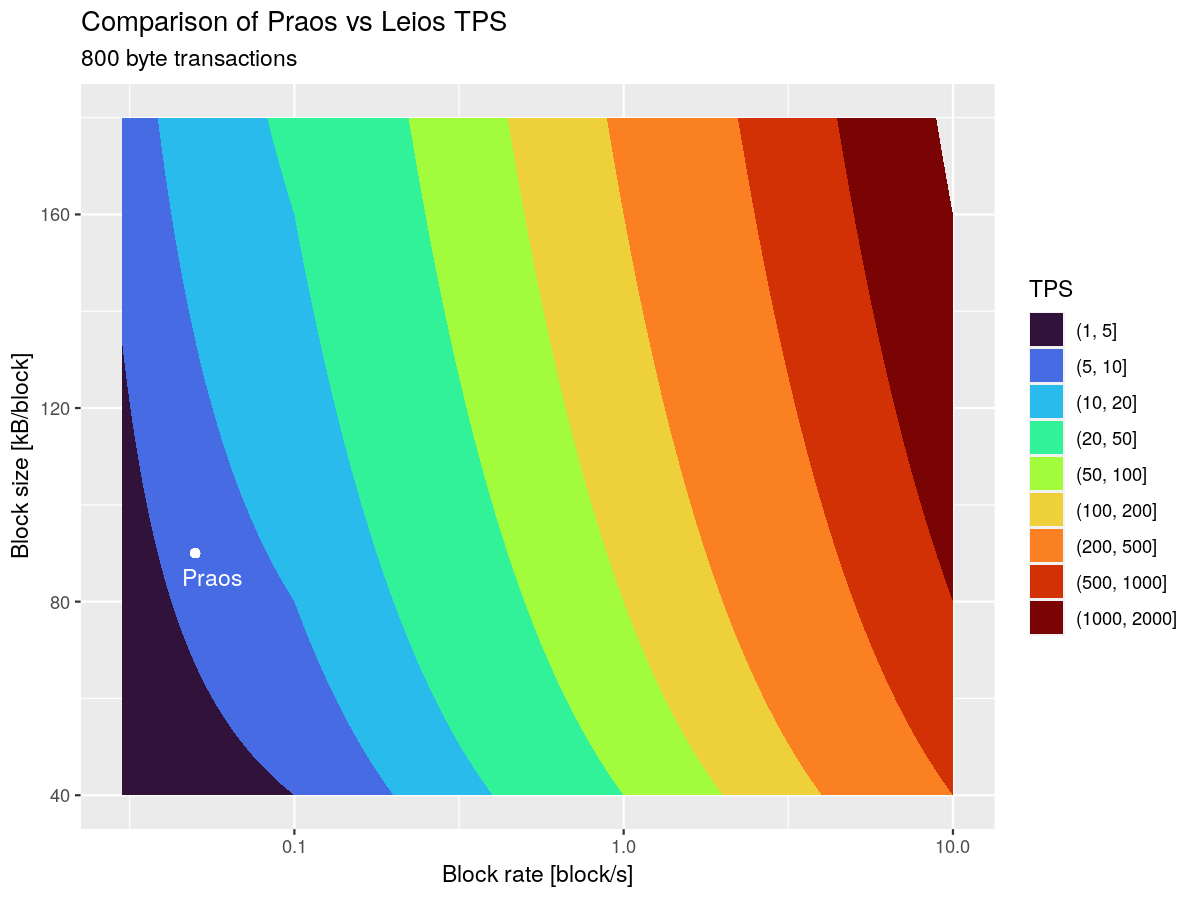
Latency
One surprising result of the simulations is related to the latency of transactions. The chart below shows the cumulative probability that a transaction will have made it into a block, at different throughputs and stage lengths.
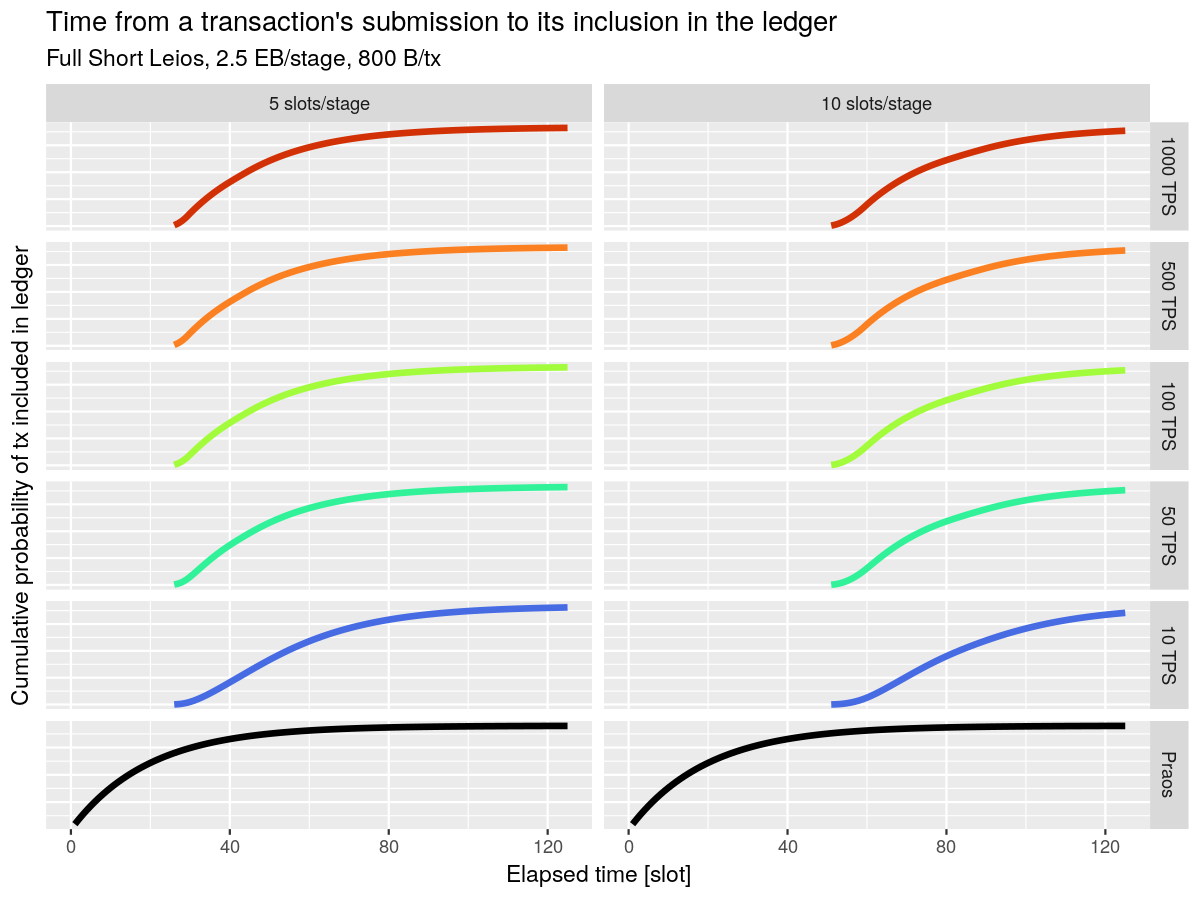
What this shows is that, while Leios adds a fixed latency to transactions, and that latency is sensitive to the pipeline length, it’s largely independent of the throughput target! We can push Leios to fairly high throughputs by paying a fixed cost of latency!
Additionally, while this may seem damaging to the user experience, when combined with Peras it likely won’t materially change the length of transaction finality.
Today, with Praos, the story around a transaction is “I have decent confidence in a transaction once it gets included in a Praos block, and then have extremely high confidence in the finality once 8 blocks have been produced on top of that one.” Today this is, on average, around 2-3 minutes.
With Leios, the story would be “I have decent confidence in a transaction once it gets included in an endorsement block, and then have extremely high confidence in the finality once 8 blocks have been produced on top of the ranking block.” This would represent a duration of, perhaps, 3-5 minutes.
With Leios plus Peras, the story would be “I have decent confidence in a transaction once it gets included in an endorsement block, and then have extremely high confidence in the finality once a boosted ranking block is produced.” This would represent a duration of, perhaps, 1-3 minutes.
State growth
“State growth” refers to how quickly the permanent storage requirements of a blockchain grow. For example, currently, Bitcoin requires 656.14 gigabytes of storage, and that grows approximately 86.6 gigabytes per year. Ethereum, on the other hand, currently requires 1.3 terabytes of storage, and that grows by 217.42 gigabytes per year.
Cardano currently uses 193 gigabytes of storage, and is growing roughly 28 gigabytes per year. If throughput increases dramatically, that growth rate will increase just as dramatically.
This is a particularly important metric because it impacts the long-term costs of running a node. Each gigabyte of data added to the chain is a gigabyte of data that has to be stored and synchronized between every node, effectively forever. There’s a common accounting technique for pricing this permanent storage: historically, storage has gotten 15% cheaper every year, meaning that an integral of the cost converges to a finite amount. Using this accounting, the cost of storing 1GB of data forever is expected to be roughly the same as paying for 80 months of storage at the current price.
After Leios, it’s likely that the next big innovation we will need to explore is how to tackle this state growth. We could, for example, have a protocol whereby ancient history is sharded among a subset of nodes, rather than being replicated by the entire network.
Network Bandwidth
Leios is designed to optimally saturate the bandwidth available to the network. It’s not surprising, then, that our simulations project that the biggest increases to the cost to run a node under Leios will likely come from the extra data transmitted outward from a node, known as “Network Egress”.
Unfortunately, this is also one of the hardest costs to estimate, because the cost per gigabyte varies so widely across cloud and network providers. If you’re curious, one of the best ways to grapple with these costs for yourself is to play with the numbers in the cost calculator the Leios team has built. Just be aware that these numbers are still preliminary.
Profitability
The combined effect of state growth and network bandwidth dominates the added costs for Leios, but the upside is that the transaction fees also contribute to revenue for the node operators. We can reproduce our chart about Praos node profitability above, but this time for Leios. These numbers are hard to estimate, as they depend on many conflating variables, but at least the general trends should become clear.
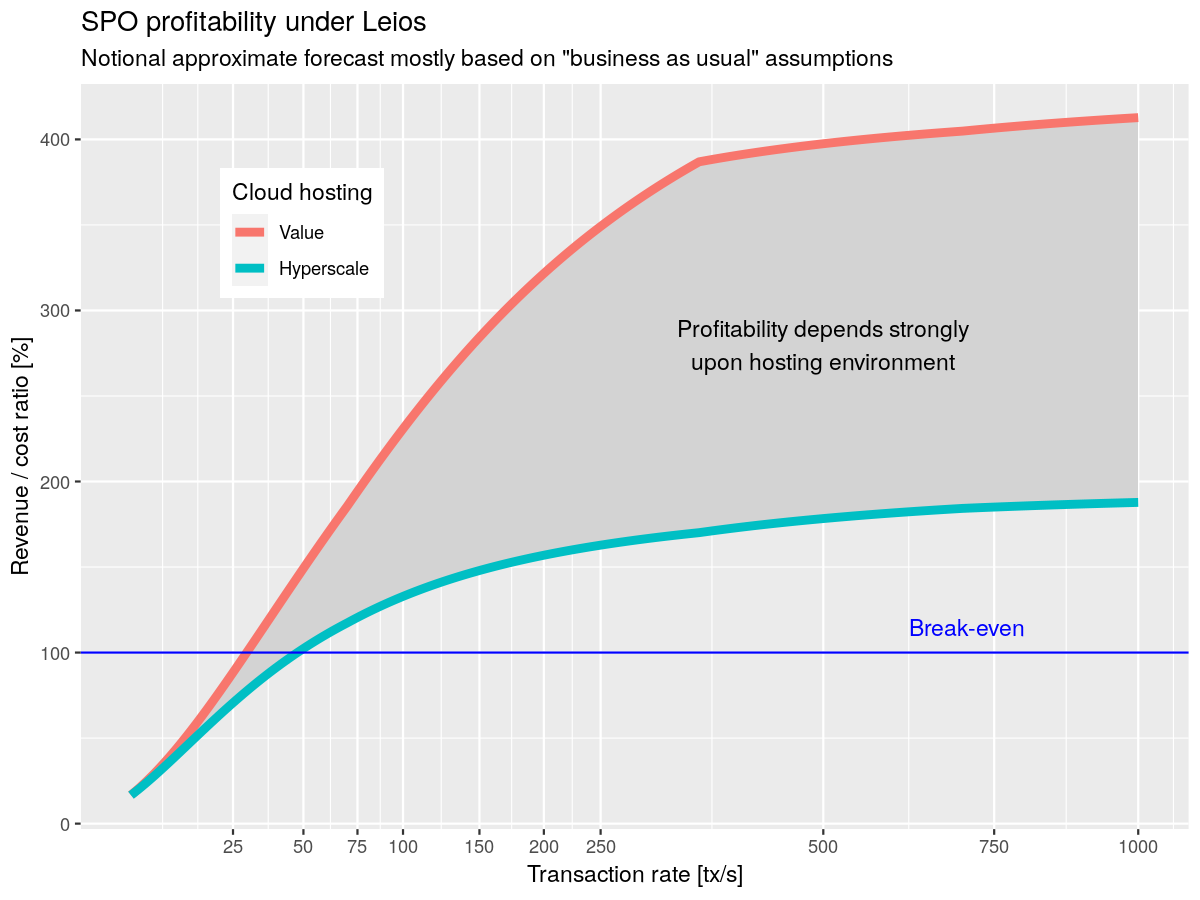
Note that the horizontal axis uses a square root scale, to emphasize the shape and key points of the curve.
Leios allows the protocol to scale well beyond the break-even point and ultimately drive cheaper fees for users while staying sustainable, making Cardano competitive in the Blockchain landscape.
Transaction Conflict
And now we come to the main topic that inspired me to write this blog: how to deal with conflicting transactions. This topic is the last major design hurdle remaining for Leios, and while we have multiple potential designs, they each involve sensitive tradeoffs that ultimately will be the broader Cardano community’s responsibility to decide on. We have several proposed designs that we’re fairly happy with on different dimensions, which I’ll outline, but it’s likely to be a contentious topic. Because of that, it’s very important that we approach the conversation with a thorough understanding of exactly what is, and what isn’t, possible and being proposed.
Here is a series of logical propositions that appear to be true, and create a fundamental tension in the Leios design:
- Any sufficiently high throughput design must eventually begin making concurrent decisions about which transactions to include
- Given that those decisions occur outside of each other’s light cones, there will be cases where those decisions conflict
- The optimistic, conflicting decisions must be resolved eventually
- Given the high throughput, each of those decisions, or the resolution, will involve a significant amount of computation
- Any nontrivial computation likely needs to be compensated by the network in some way, to ensure people will bother to do it
- An adversary that can leverage or amplify any un-compensated work can cheaply deny service to other users
The above reasoning is carefully kept very generalized: it’s not about any one particular design. What this means is that seemingly any design we settle on for Leios that has sufficiently high throughput will create tension between the following properties:
- Network Security - If a transaction incurs significant computation on the network or is persisted into the permanent state of the chain, some user pays a fee to cover this cost.
- Fee Security - A user pays a predictable fee associated with their transaction if and only if it is applied as intended to the ledger (and thus does not conflict with other transactions).
- Performance - Transactions are produced concurrently and without coordination, and reach high confidence of inclusion in the final chain in a short period of time.
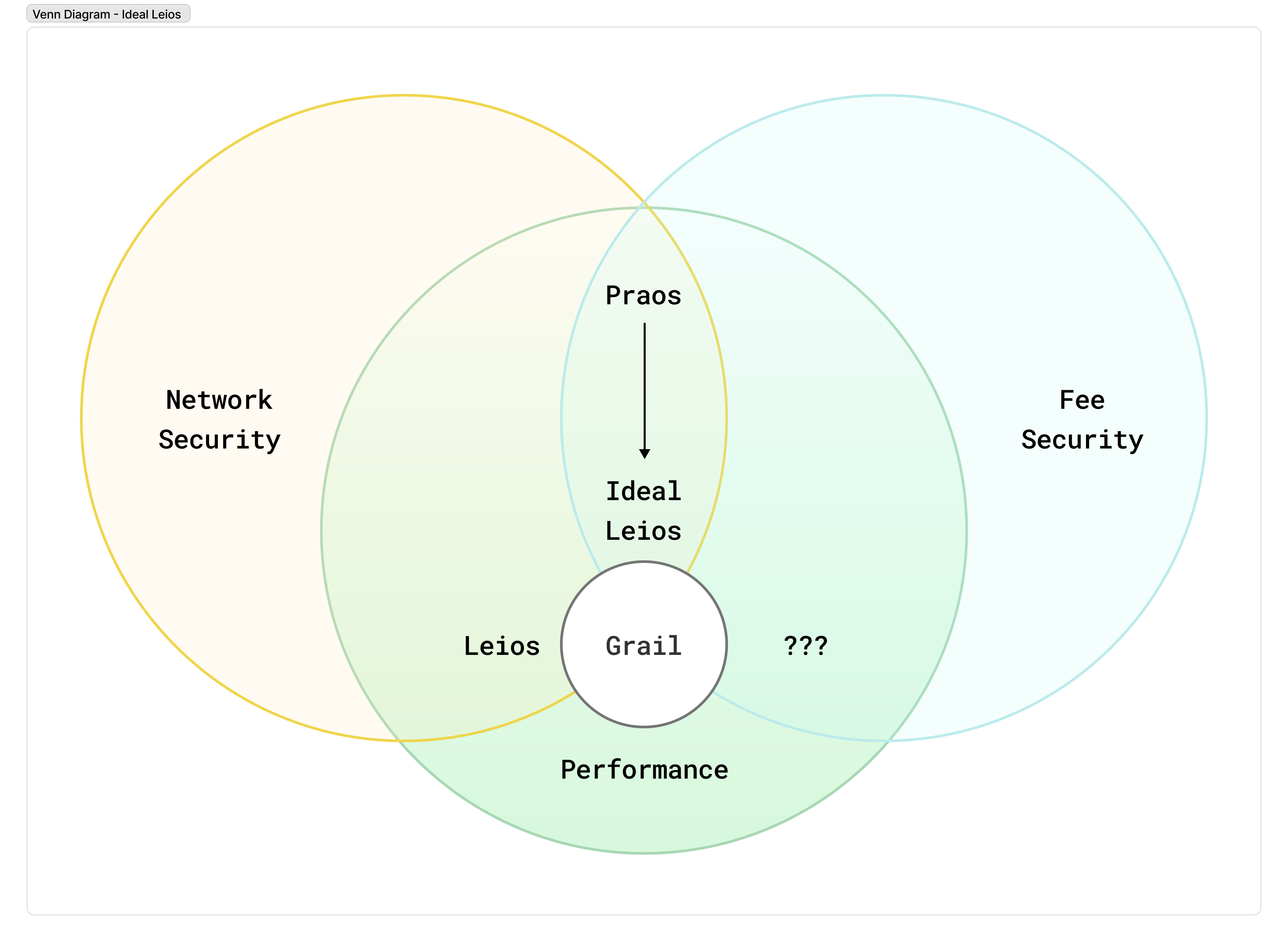
In the above chart, Fee Security and Network security are properties that a protocol can have; and performance is a gradient, which we want to optimize as much as we can within those constraints.
Optimizing for any two of these properties too thoroughly seems to make the third difficult. Praos optimizes for Network Security and Fee Security, by having a long enough quiet period between blocks so that decisions about which transactions to include are not produced concurrently too frequently. Leios attempts to optimize for Network Security and Performance; As described so far, Leios would likely need to sacrifice fee security. And so, we should examine this tradeoff, to identify if there’s a more comfortable point in the design space that gives us both properties, while still giving us the performance gains of Leios. (Note: we find it hard to imagine someone choosing to optimize for Fee Security and Performance, so we have no examples to give of a protocol that sacrifices Network Security!)
Determinism
This property is often called “transaction determinism” on Cardano. That is, a user is able to know two things: 1) Their transaction is either completely applied to the ledger, or not at all. 2) If it is applied, they can compute exactly the delta that is applied to the ledger state (including the fee they will be charged).
Note: Some people take umbrage with this term; They assert that ALL blockchains must be deterministic because given the same inputs, every block producer must arrive at the same result. However, it’s my opinion that this isn’t a useful distinction or definition to make. If a definition applies to everything or nothing, then it serves no purpose in the language: it doesn’t allow you to meaningfully differentiate two different cases. I personally prefer to assign a useful definition to “deterministic”, laid out above. A transaction on Ethereum, for example, is not deterministic from the users’ perspective, specifically because they cannot know all of the inputs to their transaction, and so its behavior is, to varying degrees, indeterminate. Regardless of what label you want to apply to it, however, what’s important is that you know that when I say transaction determinism in this article, that is what I mean.
Within Cardano, we are quite proud of this feature. It leads to a wonderful improvement in user experience because the alternative is painful and expensive. On Ethereum, for example, during periods of high load or volatility especially, users can get caught in a loop attempting to submit a transaction and having it fail, charging them for the work that has been done evaluating the smart contracts. Sometimes this fee can be in the tens of dollars for each failed transaction.
How does Praos achieve this today?
First, the designers of Praos have gone to great lengths to separate the work done to validate a transaction into two categories. One of those categories is the computation that is likely to be very and unpredictably expensive: running smart contracts. The other category is those that can be made incredibly cheap. We call these “Phase 2” and “Phase 1” validation rules, respectively.
The genius here is that all sources of non-determinism only show up in, and change the result of, phase 1 validation. This means that a node only ever has to run the scripts for a transaction once.
For example, smart contracts cannot view the current slot: the exact slot that a transaction gets included in isn’t known at the time you build the transaction, because we don’t know what the leadership schedule will be. However, you can set an upper and lower bound on the slots that a transaction is allowed to appear in, and those bounds are exposed to the smart contracts. The bounds will never change, so as time passes, you don’t need to re-run the script with a new slot number. On the other hand, the upper bound on a transaction can pass, making the transaction no longer valid. However, in that case, “revalidating” this condition is as simple as comparing two integers.
This cost is so low that a node is likely to do it for free, and an adversary is unlikely to be able to cheaply overwhelm a node with validity range checks.
Another example is checking whether each transaction input has been spent or not.
In the best case, a node validates the smart contracts of a transaction as it receives it and places it in the mempool, and then includes it in the next block it forges, or cheaply evicts the transaction from the mempool when a new block comes in, and the node only ever evaluated the scripts once.
In the worst case, a node receives a transaction, validates the scripts, and places it in the mempool. Then, they observe a block that conflicts with that transaction, validate it (including running the scripts), and evict the conflicting transaction from its mempool. The validation for the transaction in the mempool was “wasted”, but this is bounded to at most two validations. An adversary cannot amplify this wasted effort arbitrarily for four reasons:
- Two conflicting transactions will never be placed in the same mempool, meaning that each block with a conflicting transaction only invalidates a bounded amount of work.
- Transactions are not placed back into the mempool when switching forks, meaning those transactions can only represent wasted work once.
- The average time between blocks is large, meaning nodes aren’t CPU-bound. There is a huge gulf of space between blocks (on average) to absorb that extra computation.
- CPU usually isn’t metered: you pay for capacity, and so long as that capacity isn’t filled, the cost to the node operator is the same.
In Leios, however, the above isn’t necessarily true:
- The high rate of IB production means that a transaction is likely to be included in a block before the gossip protocol can alert you to a potentially conflicting transaction.
- The higher throughput means that there’s more computation to fill up that capacity and thus less forgiveness of wasted effort.
- The pipelined nature of the protocol also means there are fewer quiet periods that can absorb this work.
This means that Leios is more sensitive to an adversary creating and propagating these conflicting transactions to different parts of the network. It becomes more essential to charge for this work to prevent adversarial behavior, or at least to make it costly for such an adversary.
Does this mean that Leios is going to force us to give up our beloved “transaction determinism”? At this time, while we believe that Leios will require some “softening” of this property, we have multiple designs that allow us to provide 90% of the benefit to the user.
Said more plainly: If we assume that we want a blockchain that is secure, robust, and decentralized, then we cannot have both perfect determinism and high throughput. Praos sacrifices high throughput in return for perfect determinism. And Leios offers us the opportunity to soften that determinism in return for throughput. Exactly how much we soften this is an open design question that we, the Cardano Community, ultimately get to decide.
Duplication
It’s worth making a small aside here to observe that even without introducing an adversary, Leios (as described) has a simpler, related problem around duplicated effort. If you propagate transactions across the network, big chunks of the network will end up with the same, or very similar mempools. Thus, if two nodes produce input blocks concurrently, it’s highly likely that they will have largely the same contents. It doesn’t do much good to produce blocks concurrently if they’re just replicating the same work multiple times!
This is similar to but weaker than, the issue described above. Indeed, a transaction “conflicts” with itself exactly because it spends the same inputs! So while it doesn’t amplify the work done, duplicate blocks do waste the capacity of the network.
Ultimately, there is a diverse space of solutions to these problems that we’ve been exploring. Some of these we’re very early in the analysis process, some of these are not mutually exclusive, and the best approach may be a combination, and some of these only solve the problem under honest assumptions, and still need something further to address an adversary. Still, despite not having a clear and definitive recommendation for which of these is best or a complete understanding of the tradeoffs, I’ll walk through them to give you a look at the incredibly rich landscape we’re considering. We’d love to hear community feedback on these different choices!
Deduplication
The simplest solution to this problem, and to avoid both duplicated effort and duplicated storage, is to design the protocol to support “tombstoning”. The idea here is to design the block hashes in such a way that duplicate and conflicting transactions can be pruned from the protocol. A purely duplicate transaction doesn’t need to be validated twice (it is simply recognized as duplicated and skipped), nor does it need to be stored a second time on disk.
Similarly, we can employ the notion of a “tombstone” to prune conflicting transactions from the history and keep the permanent ongoing cost of honest conflicts low.
In such a strategy, the ID of the input block would be defined, not as the hash of all of the transactions concatenated together, but as the hash of the IDs of each transaction concatenated together. When a transaction conflicts and gets filtered from the ledger, then once it gets written to the immutable portion of the chain, it can be deleted, keeping only the transaction ID. You can think of this like a “tombstone”, marking a pruned transaction, where the transaction ID is the epitaph. Since the ID of the input block is defined by the hash of all the transaction IDs, you still have enough information to reproduce the input block hash.
When someone is syncing from a peer, they still need confirmation that the transaction was indeed conflicting with another transaction that eventually makes its way into a ranking block. To that end, the endorsement block records which transactions were conflicting. Since the endorsement block has a certificate from the majority of the stake on the network, this gives high confidence that the transaction was indeed in conflict and was safe to prune. Perhaps this serves as an “obituary”, confirming the validity of a tombstone.
These tombstones aren’t valid in the volatile region of the chain, while we’re still reaching consensus, since nodes still need to know whether to endorse the block. But they do allow you to prune the historical state, minimizing the ongoing costs. You simply defer validating an input block with tombstones until you see the endorsement block with the obituary. If one never materializes, that fork is invalid and you look for another peer.
This alone doesn’t resolve the problem with conflicts in the presence of an adversary, however. A malicious actor can still flood the network with invalid transactions, filling up throughput capacity on the network with conflicting transactions that don’t cost them anything. This denial of service attack means we need to look for other solutions as well.
Coloring
Another “honest party” friendly solution is the notion of transaction coloring. Each transaction is randomly (or even explicitly, to assist with transaction chaining), assigned a color. When an input block is produced, it also has a color, and only includes transactions of the same color. If a node runs out of transactions to include, it can deterministically derive another color and continue including transactions from that color.
This allows different nodes which produce input blocks concurrently to ensure that the contents of their blocks are shuffled, so we avoid wasted/duplicated effort.
It doesn’t, however, prevent an adversary from intentionally crafting conflicting transactions that have different colors. They can vary some small innocuous property of the transaction until the hash places it in a different color, and create an adversely high percentage of wasted effort and capacity for the network.
Sharding
One way to extend the “coloring” idea above to harden it against an adversary is to go further and apply the separation to the ledger itself. More commonly referred to as “sharding,” by dividing transactions into lanes that cannot conflict by construction, and then using these lanes for our concurrent production capacity, we eliminate the problem! This works even in a probabilistic form: even if we just make such conflicts rare, even under adversarial conditions the network can afford to absorb the extra work without forfeiting any fees from the conflicted transactions.
There’s a number of ways this can work in practice, but here’s one example:
- Each transaction output is optionally labeled with a “shard ID”
- Each transaction includes a collateral field, and each collateral input must come from the same shard
- Each input on a transaction must be either labeled with that same shard, or unlabeled
- Each input block is randomly assigned to a shard, and can only include transactions from that shard
This allows users to avoid losing fees: just ensure that if your transaction includes unlabeled inputs, you don’t sign any transaction that conflicts with that one. And if an adversary intentionally creates these conflicts, the ledger can forfeit those fees.
Unfortunately, there are major challenges in designing this correctly:
First, this dramatically complicates the ledger and the user experience. At the very least wallets need to manage these labeled outputs and avoid allowing the user to sign conflicting transactions. This is also a huge potential complexity cost to the ecosystem, and upgrading all of the indexers, libraries, transaction builders, dApps, wallets, and other infrastructure is no small undertaking!
Second, it is difficult to balance the number of shards, at least while they’re produced pseudorandomly. Low shard counts mean there’s a higher probability of concurrent conflicts. Increasing the number of shards reduces the probability that they will conflict, but also lengthens the average time between the same shard recurring, which means transaction latency goes up dramatically. And there doesn’t appear to be a sweet spot, only an uncomfortable compromise where you have to deal with the worst of both worlds.
We’re still exploring this design space. In particular, perhaps the pseudorandom production of input blocks isn’t as important, and we can resolve these problems with a predefined shard schedule. This doesn’t solve the ecosystem-level complexity but could allow the protocol to keep both conflicts and latency low.
At the extreme ends of throughput (1,000, 2,000, and 10,000 transactions per second), it’s likely that some form of sharding or mutual exclusion will be needed.
However, what the analysis above makes clear is that Cardano doesn’t need 1,000+ TPS to solve its sustainability problem. In the fullness of time, this may be necessary, but in the short term, a simpler model that allows us to go from ~5 TPS to ~100 TPS would be a dramatic upgrade! There are some exciting alternative designs we’ve been considering in this space.
Collateralization
Rather recently, the Leios team has been analyzing another design that is far simpler and seems very promising, at least at lower throughput targets. Importantly, those lower throughput targets still represent a dramatic upgrade for the Cardano chain and don’t preclude more complex solutions in the future.
The main insight stems from looking at why deterministic transactions are valuable to Cardano users, and why losing them is painful.
When a user submits a transaction on Ethereum and it fails, they lose the gas fees spent processing that transaction. This is painful because the user paid for a service they did not receive. It’s analogous to walking up to the barista at a Starbucks, tapping their card, and paying $6 dollars a latte, and then the barista tells them that too many people ordered lattes and the machine is broken, but not offering a refund. If the user really needs that transaction to happen, they need to retry, and may end up paying that failing transaction fee again! Finally, the times when these failures are most likely directly correlate with the urgency of those transactions: during a hyped launch, or market volatility threatening a liquidation, it is really important to the user (economically) that this transaction goes through.
On Cardano, deterministic transactions only solve half of that problem. In cases of high load, you may still be unable to get your transaction on chain, but at least you aren’t charged for them.
Leios, implemented naively, threatens to flip this: the chain has extreme capacity, but you may end up paying for a service that you didn’t receive.
What if we forfeit a small, bounded amount of determinism, but ensure that you get the service you paid for.
The main idea here is that, with input blocks produced by a VRF lottery, then even over rather short periods of time, there is a tight distribution of how many concurrent blocks might be produced. At an average of one input block per second, and an average diffusion time of 5 seconds, we might see 5 or 10 input blocks produced outside of each other’s light cones, but we likely will not see 100 or 1000 concurrent input blocks.
Thus, the maximum amount of inherent conflict an attacker can produce is bounded in the same way. If an input block is produced inside the light cone of another, it can avoid creating conflicts with that input block.
And so in practice, if a user puts some collateral at risk in case of conflicts, that collateral only needs to be as high as this potential throughput. Even if there are short bursts of higher concurrency that allow more conflicts than the collateral that is available to pay for it, this can’t be sustained by an adversary.
And, importantly, there’s a seemingly heretical choice buried in the sand here: what if, instead of forfeiting the collateral from the transactions that get filtered from the chain, you forfeit the collateral from the transaction that did impact the ledger? So, the winning transaction pays for the effort used to validate the losing transactions.
Technically, this violates Cardano’s deterministic transaction property. Now, instead of the two outcomes described above, there are three potential outcomes:
- Your transaction has no impact on the ledger whatsoever as if it had never been sent
- Your transaction gets included, you pay the normal fees, and it updates the ledger in the way you intended
- New: Your transaction gets included, and you pay elevated fees, and updates the ledger in the way you intended
The psychology of this is fundamentally different from what we typically refer to as failed transactions. In all cases, you only pay for the services you receive! Sure, you might pay more in fees, but at the very least you accomplished what you were trying to accomplish. It’s also fairer, in some sense, since the winner is the one who got the economic value out of the transaction. If someone avoided being liquidated for 20,000 ADA (or just made 20,000 ADA on a liquidation), they’re unlikely to mind paying a little bit extra in fees.
And remember, the risk of forfeiting this is only constrained to cases where two people are able to spend the same transaction output, which largely boils down to an adversary or shared script UTxOs.
The feasibility of this now entirely depends on how big that over-collateralization has to be. If there’s a risk that you lose 5000 ADA, nobody would transact again. But if you might end up paying 1 ADA in fees as opposed to 0.2 ADA in fees, then it may be an entirely reasonable design.
This is why I mentioned it’s likely a viable solution at lower throughputs, but becomes impractical at higher throughput. At 100 transactions per second, this is roughly 5-10 times multiple on the transaction fees. So, instead of paying 0.2 - 1 ADA in fees, you might pay 2 - 10 ADA in fees in rare cases.
However, at the upper end of throughput, in the thousands of transactions per second that Leios could support, this collateralization tends to become impractical, and we may need additional solutions beyond that. But, in the interest of solving the sustainability problem and ratcheting Cardano up to the next rung of the ladder, this represents an attractive, low-complication solution with interesting properties.
There is currently no consensus on which of these solutions is the best, or if this even represents the totality of the landscape, even within the Leios research team. We’re still looking at, simulating, tuning, and debating all of these designs. Indeed, as we bring new members onto the team and solicit community feedback, assumptions are being challenged every day that help us either reach a better understanding of the nature of the problems at high throughput or reveal new ideas that are worth exploring. We provide this deep insight into our process not to invite controversy, but to lay out, transparently, what the risks and challenges actually are, and dispel fear and dogma around what people think they might be.
Closing thoughts
Wow. This blog post ended up being quite a bit more extensive than I planned. Hopefully, it was useful in building up a solid and nuanced understanding of Leios and dispelling some of the anxiety around the notion of conflicting transactions.
So where do we go from here?
The Leios team is still improving the fidelity of the simulations. We want to develop a solid understanding and predictive model of the key performance metrics of different designs and parameters. The team plans to use this predictive model to write a comprehensive CIP, which outlines these tradeoffs and the entire parameter space that the Cardano community can choose from when (or perhaps if) the Cardano community decides to deploy this upgrade.
This plan will, ideally, be broken down into a series of phases, where value can be delivered incrementally, as early as possible, and with minimal community disruption.
Next, the relevant teams within Input Output, with outside help, will begin prototyping the implementation as the community deliberates on the design, to minimize the time to market for the protocol.
In parallel, and with reference to this predictive model, business development initiatives will attempt to attract commercial interest in the new capabilities that Leios and its interim versions will bring. If you’re reading this from outside the Cardano community and I have intrigued you, please do not hesitate to reach out! There may be opportunities for strong partnerships with early pilot customers of Leios.
As that prototyping matures, we will deploy custom testnets and conduct large stress tests to validate the power of our predictive model. Expect some very fun and highly publicized events of this nature!
Using that, we will consult with technical experts throughout the community to settle on a final recommended parameter set to put up for a vote. In all likelihood, this will start small, with the knowledge that our robust governance process can scale up to meet demand.
In the end, it will be you, the Cardano Community, SPOs, DReps, and delegators, who make the final decision on whether all of the above constitutes a worthwhile upgrade to the Cardano Protocol.
