Poison Piggy - After Action Report
Introduction
On November 21st, 2025, Cardano suffered a severe degradation of service that lasted roughly 14 hours. This blog post serves as my independent record of what happened, my assessment of how serious it was, and my assessment of how the network, chain, and community responded to it.
My goals with this post are to present the cold facts and my expert opinion in sufficiently approachable language that anyone should be able to form their own opinion on. I hope I am successful in confronting the seriousness of the incident head on, making no excuses simply because I’ve chosen to build on Cardano. On the other hand, I also hope to effectively explain the nuance around the event, avoid catastrophizing, and highlight what went well. You, as the reader, will have to judge whether I did this effectively.
There will likely be endless, exhausting, and pointless debate about what terms to use to describe this. I think this kind of discussion is ultimately masturbatory, and stems on one side from people eager to see Cardano’s “no downtime” claim dethroned, and on the other side to cling to that unbroken Duolingo streak.
What matters is impact. I will describe the real world impact, and the taxonomy I use consistently to classify these events. If, after that, you decide for yourself that Cardano “went down”, I won’t begrudge you your opinion. I’m not precious about that label, and think reasonable people disagree.
What I would ask, if you want to operate in the public space in good faith, is that you form this opinion on your own, not from some Twitter talking head who has pre-decided what this event means. Or, if you are one of those Twitter talking heads, at least do your audience the courtesy of defining what your thresholds for whatever label you use are, and apply them consistently to the other, similar events I’ll describe below.
Hopefully this kind of reasonable affect is not too much to ask from Twitter, but it probably is. :)
TL;DR
- A serialization bug caused a unidirectional “soft” fork of Cardano, first on the preview testnet, then on mainnet
- A fix was released shortly after the discovery on testnet, before the issue occurred on mainnet
- This fork seriously degraded quality of the chain, but not as severely as you might think
- Transactions submitted via robust infrastructure were delayed by up to 400 seconds
- Time between blocks on the now dominant chain grew to a maximum of 16 minutes
- Some infrastructure may have created longer delays due to unrelated fragility
- Roughly 3.3% (479 out of 14383) of transactions didn’t make it into the fork that is now dominant
- Some systems, particularly bridges or exchanges, were exposed to replay / “double spend” risk
- Analysis of the transactions on the discarded fork is still underway to determine if any of that risk materialized as actual damages
- This constitutes a serious degradation of service for users, but within expected bounds for a high nines availability of service
- The 3 founding entities, plus Intersect and countless community projects (including Sundae Labs), collaborated to identify and fix the issue, and in making a recommendation to the SPO community on which fork to choose (via which versions they run)
- The SPO community organically endorsed that recommendation, upgrading their nodes, leading to a full organic recovery in roughly 14 hours
What happened
Here is, as best as I’ve been able to put together, a complete timeline of the relevant events on the chain. (All times are in my timezone, EST).
- On Nov. 20th, 2025, at approximately 15:39, someone submitted a transaction to the preview testnet, which was accepted by some nodes, and rejected by others. This was likely accidental, though we don’t know for sure who or for what reason this transaction was submitted.
- At approximately 18:19, I was tagged by HomerJ in an “SPO-testnets” channel, where the issue was being triaged, because one of the blocks around that time contained SundaeSwap transactions (this would ultimately be a red herring, but it made me aware of the issue).
- I checked SundaeSwap infrastructure, and shared some relevant information, such as what versions we were running, and which fork we were on. As a policy, we avoid upgrading our infrastructure until we are forced to via a hard fork or a security vulnerability.
- Early diagnostics indicated cardano-db-sync was crashing due to a serialization error of some kind. We thought perhaps this was the root cause, rather than a network partition or chain fork issue, since it would impact what we see on chain explorers nearly universally. Since (as far as I know) all blockchain explorers are built off querying cardano-db-sync, this meant we were flying blind, as the tools we usually use as our eyes to inspect the state of the chain were either stuck, or following a very low density fork of the chain.
- After comparing the tips from multiple chains, it became clear that there was indeed a fork in the chain, and it was correlated to node versions. Sundae Labs was running an older version, which followed what would ultimately be considered the “healthy” fork, and so I coordinated with Ashish from Cardanoscan to open our relays to his infrastructure to read from my fork, which restored our eyes.
- I began direct messaging with Sam Leathers, chair of the Cardano Product Committee. He had been able to quickly code up a diagnostic tool that found the divergence between the chains. (Side note: big win for the Amaru team here, as the libraries we produced served as a foundation for this tool!)
- Using this tool, he was able to furnish the raw bytes of the transaction, and also invited me to join the google meet call between core IOG and CF engineers.
- At around the same time, Andrew Westberg and I identified the faulty hash in the transaction: a delegation certificate to a pool identifier that was twice as big as it should be. Instead of delegating to pool EASY1, it delegated to EASY1EASY1. (Note: the actual delegation certificate references the pool by hash, but I use the ticker here to illustrate the point).
- The ledger team was able to quickly track down the bug, and when it was introduced, and produce a fix.
- On Nov. 21st, 2025, at approximately 03:02, a similar transaction was submitted to mainnet. This one delegated to RATSRATS, where RATS is Charles Hoskinson’s personal stake pool.
- I woke up around this time (by pure coincidence; I’m suffering from a fairly bad cold and was very restless that night), and saw the initial messages reporting that mainnet was suffering from a similar issue.
- I decided that there wasn’t much I could contribute, as Sundae Labs infrastructure was all already on an old version without the bug, but the following day would need people to pick up the mantle with renewed energy, so I made the decision to try to get more sleep while others worked on remediation.
- Overnight, IOG, the CF, Emurgo, Intersect, many exchanges, many SPOs, et. al. upgraded nodes to the patched version. Collectively, the official recommendation was to choose the fork that was more restrictive. In theory, choosing the more relaxed chain would have resolved the chain fork faster (since it had the majority of stake), it would have created two main challenges: a. A fix was already released while the impact was only the testnet, and trying to change direction would have muddled the comms, creating confusion about what the actual recommendation should be. b. It was judged that offchain tooling, wallets, exchanges, etc. would have likely been disrupted for much longer. So while the chain itself might have recovered quickly, the ecosystem itself would have been impacted for much longer.
- The other chain was nicknamed the “pig” chain, likely because of the “fat” pool delegation, and the officially recommended chain was nicknamed the “chicken” chain.
- At around 4am, existing infrastructure monitoring tools were successfully updated to begin collecting metrics on the pig chain, so we could monitor the progress and likely outcome.
- In the background, several people began trying to identify who the culprit was, mostly to determine if we should expect further attempts to disrupt the chains recovery.
- From 4am to 10am, the chain was divergent, meaning the faulty transaction on the pig chain would become fully immutable before the chicken chain overtook it. If this happened, all nodes who were following the pig chain would need manual intervention to recover to the longer chain: they would need to be stopped, their database truncated, and then replayed up to the longest fork.
- By 11am, a beam of sunshine broke through the clouds: the estimated time for the poisoned transaction to reach immutability was now longer than the time it would take the other fork to catch up. At this point we knew the chain would very likely fully recover within 18 hours.
- At this point we largely just monitored the chain, ensuring we had full data dumps for analysis for any after action reports such as this one.
- The time to recovery inched down as more and more SPOs made the upgrade, and at roughly 17:16, the chicken chain overtook the pig chain. Since this chain was still valid according to those following the pig chain, they switched to the chicken chain on their own and the chain fully recovered.
Root cause
In case you missed it, here’s an explicit restating of the root cause of the bug:
- When parsing hashes (such as pool identifiers, transaction hashes, addresses, etc), each type of hash has an expected length (28 bytes, 32 bytes, etc.)
- In theory, providing a hash that is too short or too long should be considered incorrect
- Older versions of the node correctly rejected hashes that were too long
- A commit made a year ago, on November 24th 2024, introduced an obscure code path that would accept hashes that were too long, and just truncate to the correct length, discarding the bytes that aren’t needed
Analysis
As background reading, I suggest reading my previous description of Ouroboros Praos.
Here’s some interesting pieces of data and charts that I came across throughout the event.
Chain Heights
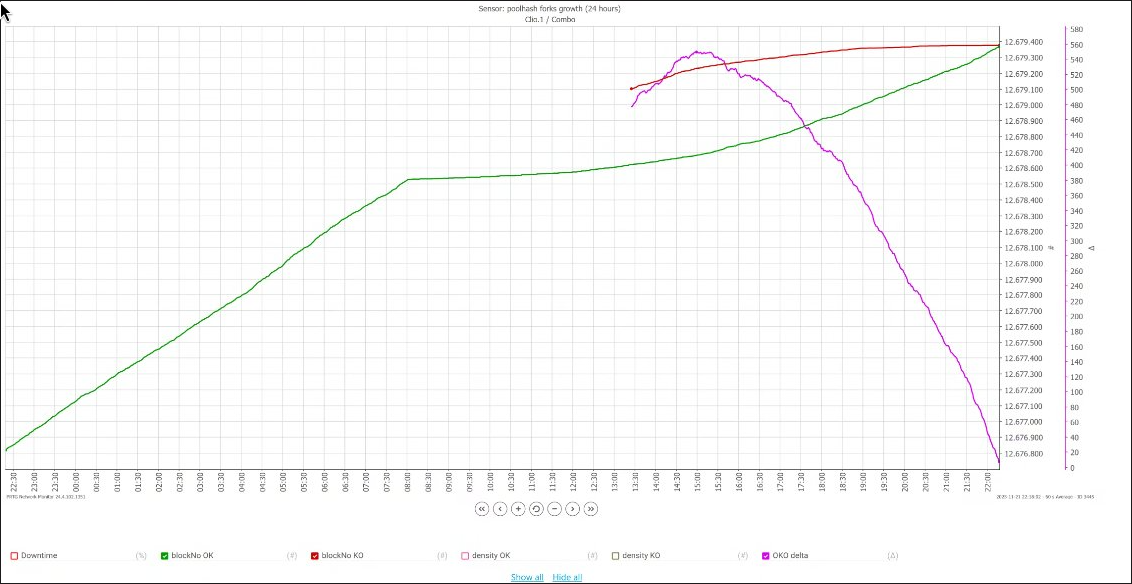
The above chart shows the chain height of the chicken chain (green) over time; the height of the pig chain (red) over time, and the gap between them (purple).
This is the chart we were constantly refreshing to track the rate of recovery. Here’s what it looked like when I woke up, right around when the situation started to turn around.
Significance: This shows the very clear and predictable path to recovery predicted by / selected for by the design of Ouroboros. We were able to predict, a few hours in advance, exactly when the chain would recover.
Convergence
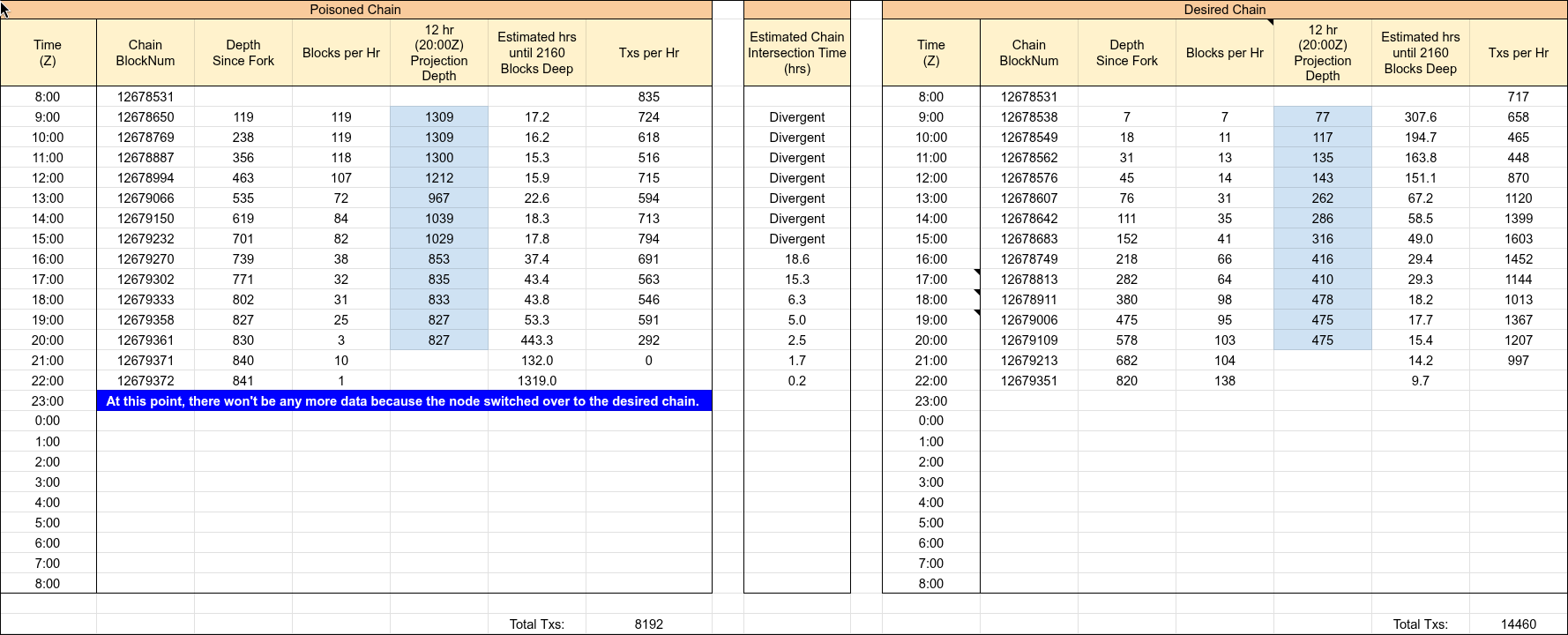
The table above shows the tracking that was going on during the event, showing the rate of blocks per hour on each fork, the time until the poisoned transaction became immutable, and in between them, the time until recovery.
Here’s that same data represented on a chart:
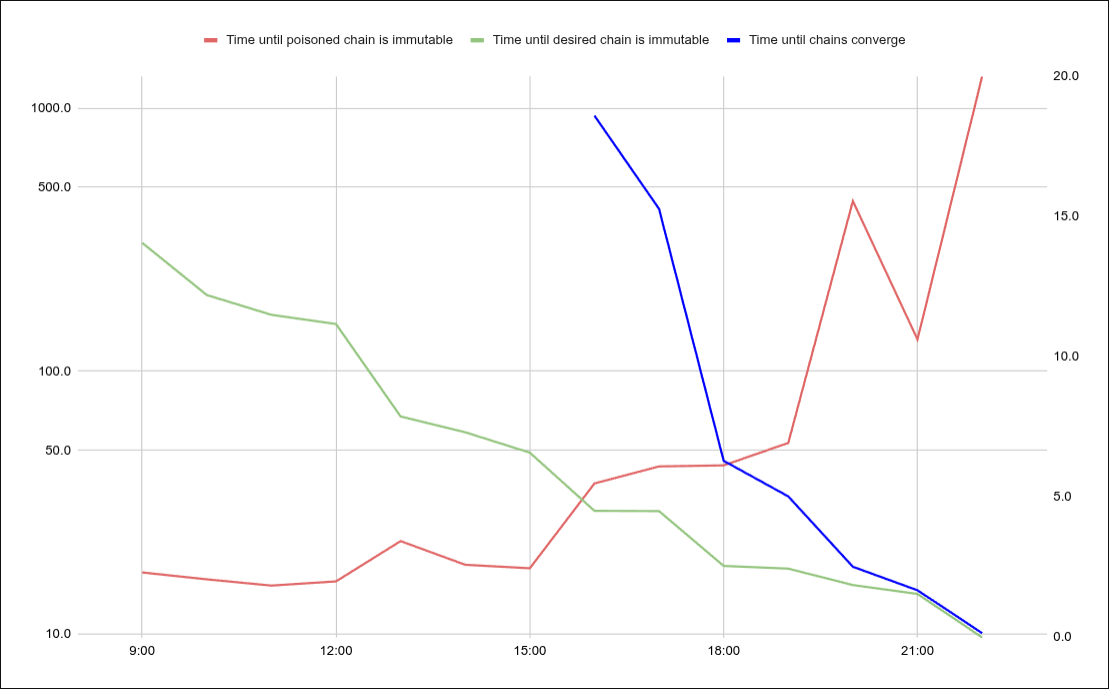
Significance: This shows how “fluid” the stake on Cardano is in reacting to and upgrading infrastructure. The fact that the pace of recover accelerated is a direct measure of this.
Time between blocks
One thing that helped the recovery is that as stake started to shift, time between blocks on the pig fork grew, and time between blocks on the chicken fork shrank, which you can see on this chart:
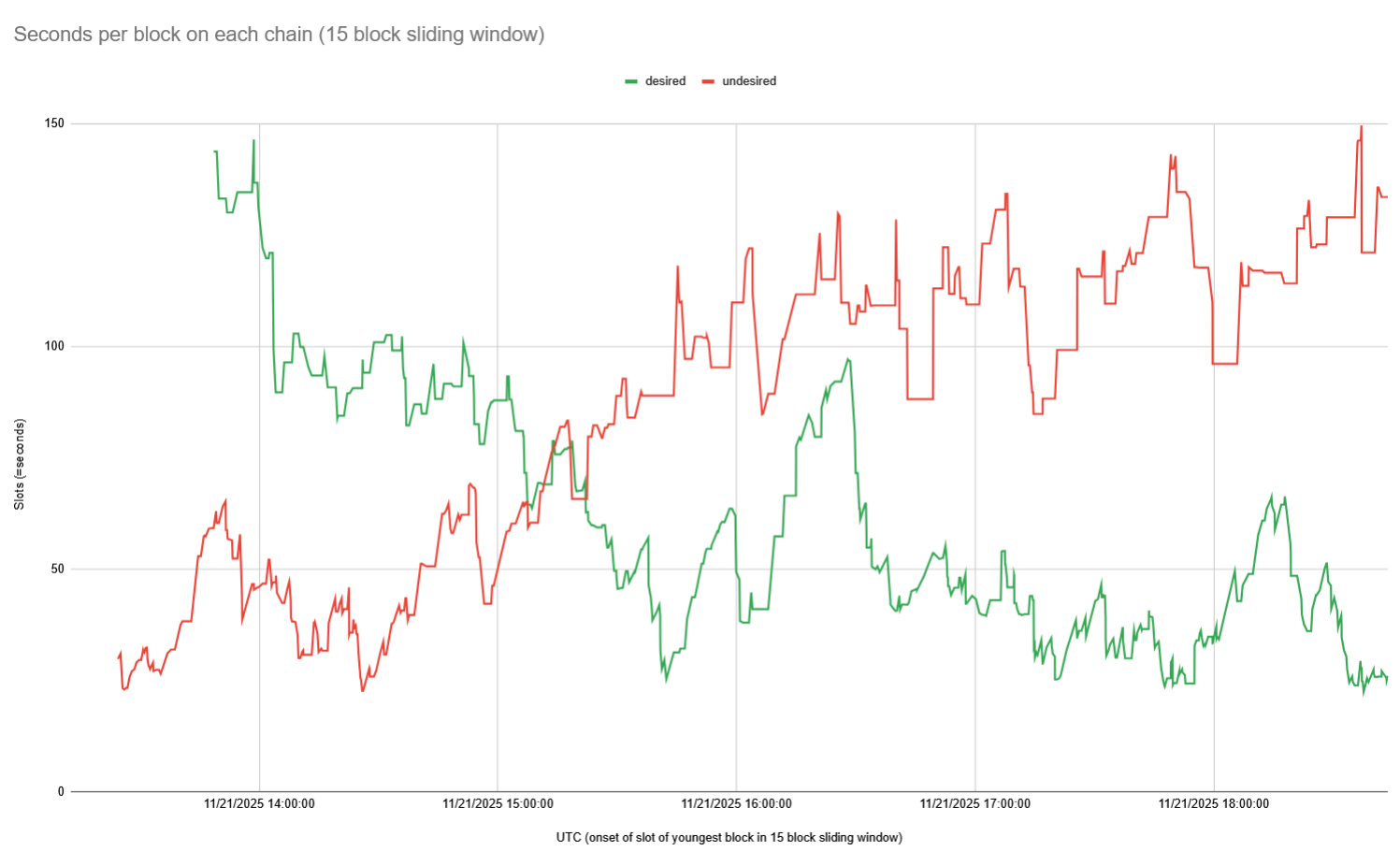
Significance: This shows how the success of one chain leads to the dwindling of the other.
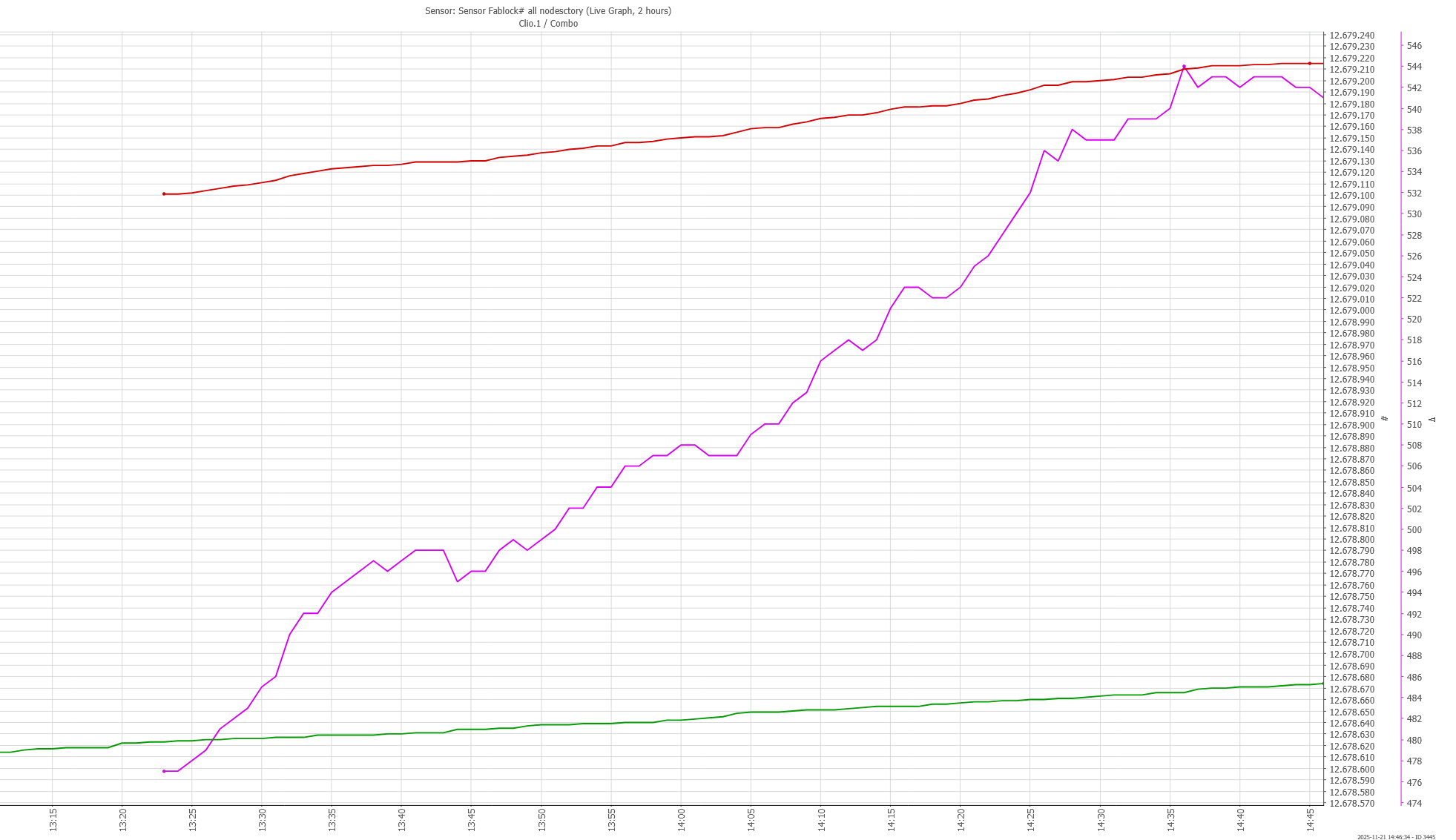
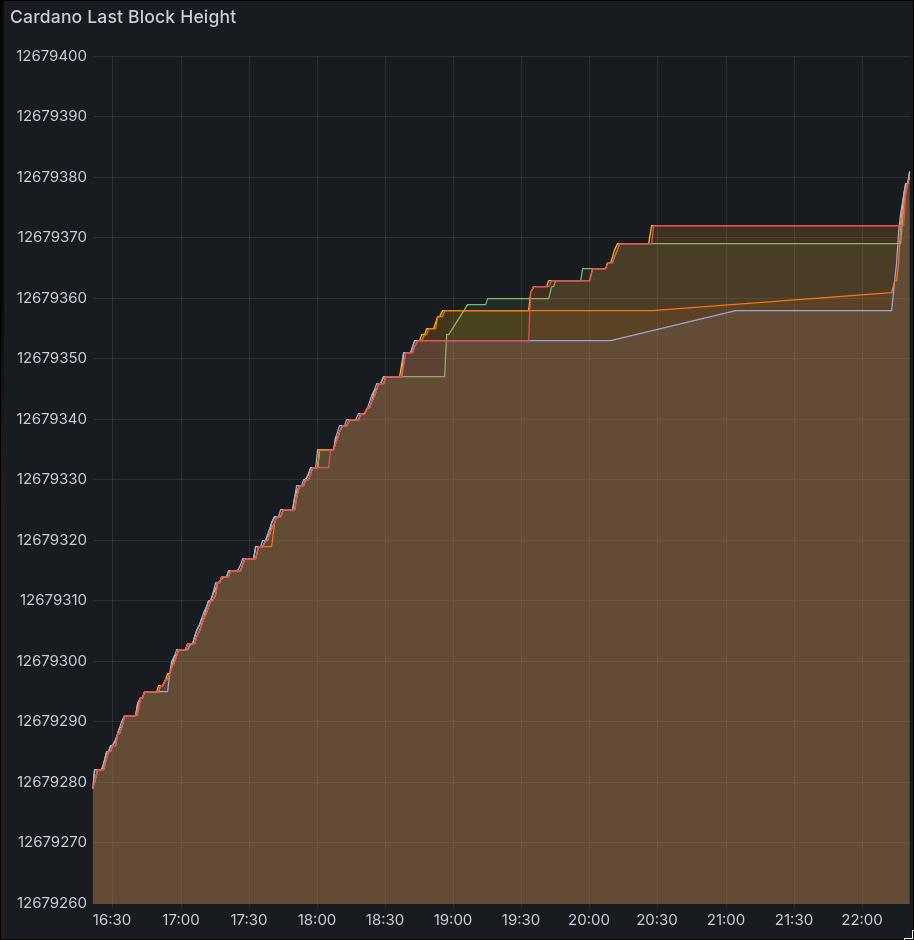
Chain switch
Here’s the moment that several of the monitored IOG nodes gave up on the pig chain and switched to the longer chicken chain:
And here is a video of the same moment, live, as seen by PoolTool.
Significance: This is the concrete evidence of when the nakamoto consensus worked as intended and converged the network to a single canonical history. You can see each relay level off in block height as the propagation of the pig chain grew worse, until they all recovered to the chicken chain (jumping in height) in a tight bundle.
Canary Transactions
The Cardano Foundation runs a service that periodically submits “canary” transactions to mainnet. These are simple value transfer transactions with various validity ranges, to measure the real-world inclusion delay for transactions in the network. That is, for a typical user, how long are their transactions taking to settle on-chain.
Here’s the graph of inclusion times over that time interval:
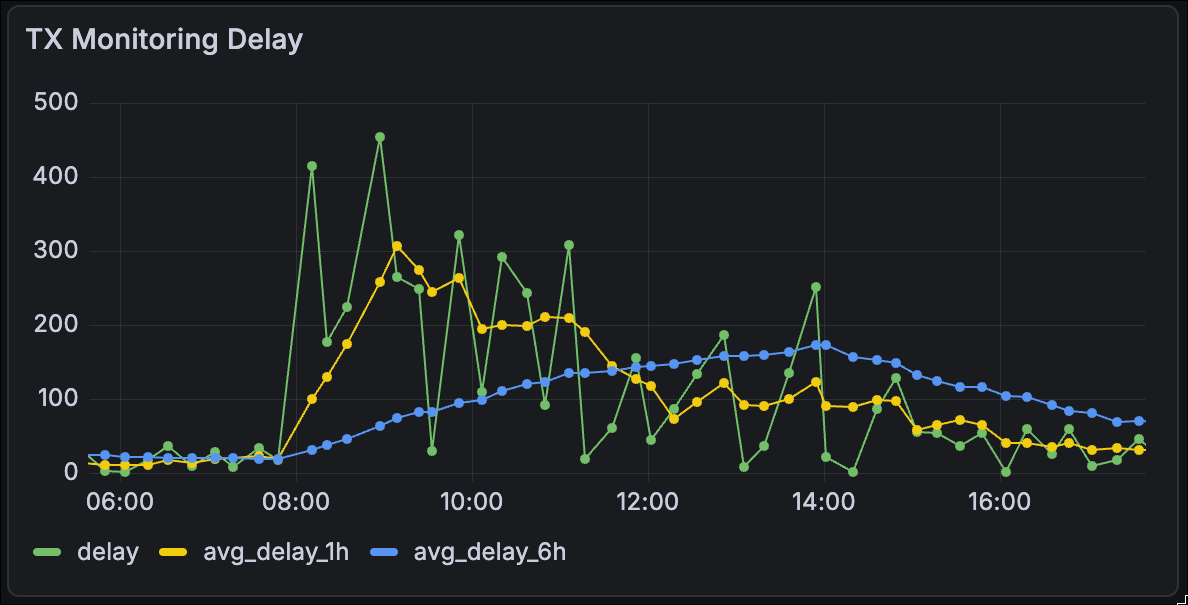
You can see that this spiked up to individual cases of ~450s, or ~300s when averaged over the span of an hour, before slowly converging back down to close to 20s.
Signifigance: This measures, objectively, what the typical user experience during the event likely was: around 5 minutes of delay for their transaction to make it on chain. Some users may have had a different experience, but this was likely caused by other 3rd party infrastructure like the wallet or the dApp. These are definitely areas for us to focus on.
Chain Quality
Another interesting metric to look at is the “chain quality”, which is a measure of what percentage of “expected” blocks are being produced. This usually fluctuates above and below 100% as block times are a randomized schedule.
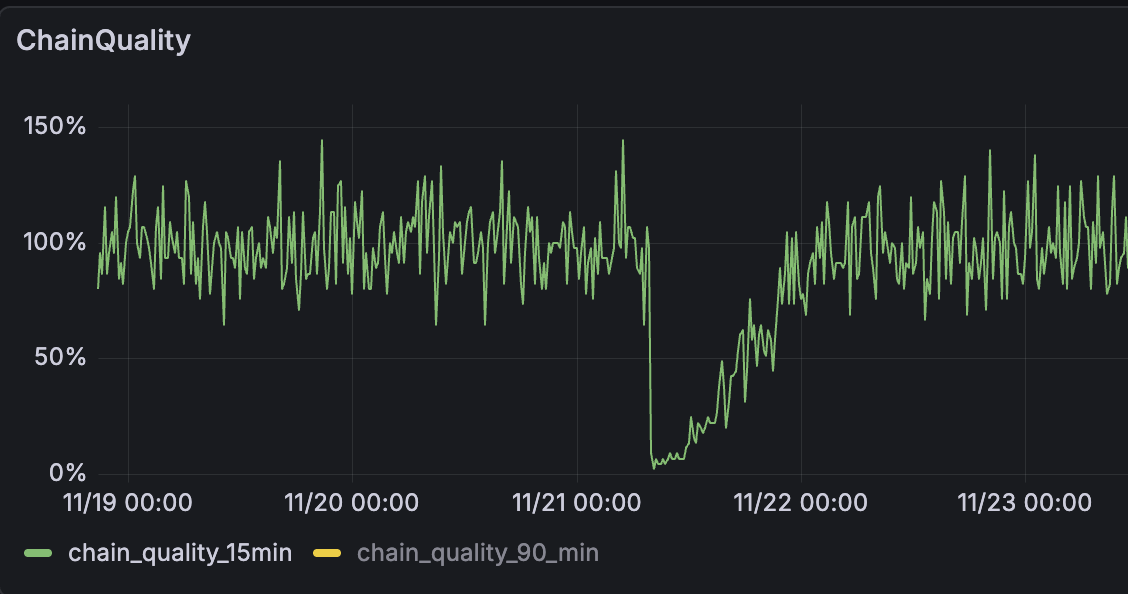
Significance: This visually shows the impact on block frequency and its recovery over time.
Mempool
By pure coincidence, the Leios team was running experiments to measure how often a transaction reached a nodes mempool before being seen in a block. This gave us lots of interesting insight into how the mempools behaved during this event.
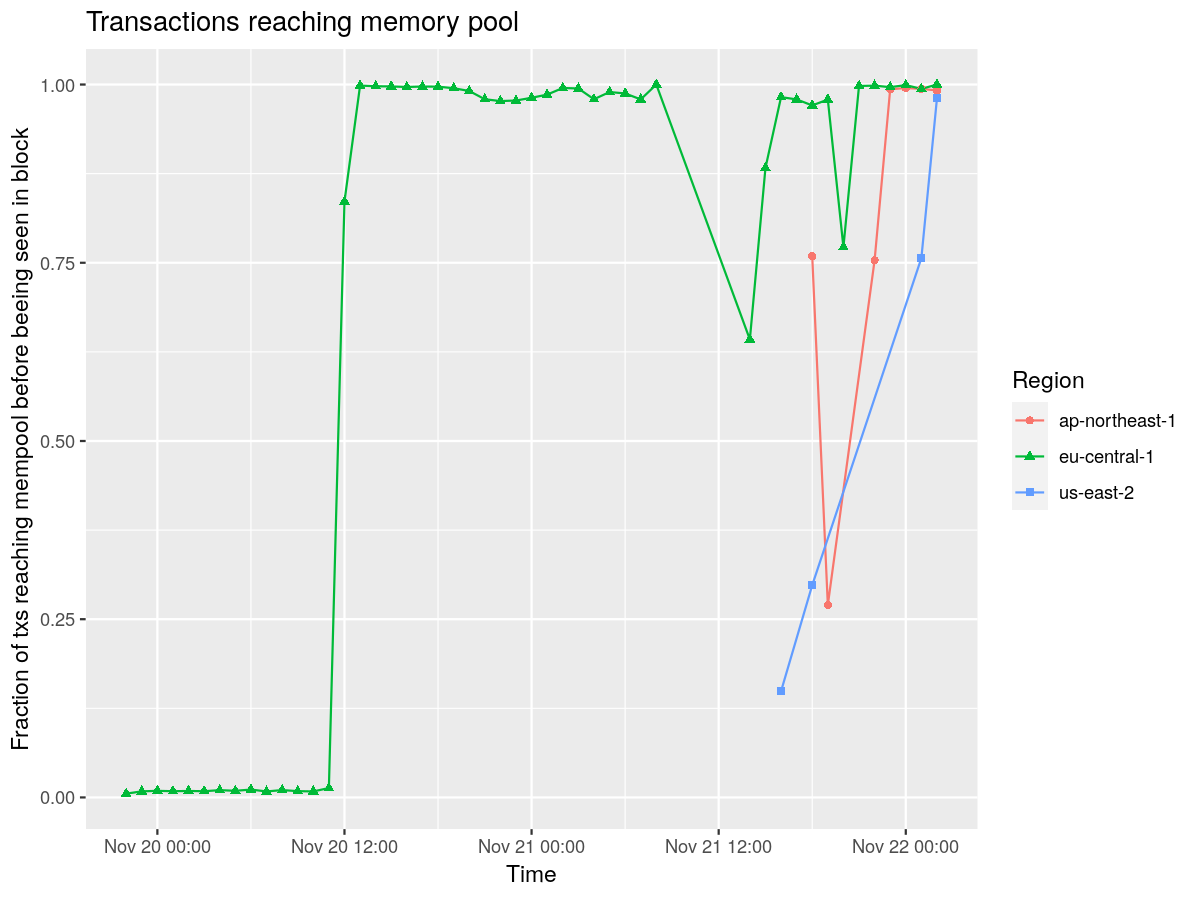
Note that the important line here is the green one, as the team was still spinning up the nodes in other regions. Also worth noting that the large green dip is because of the need to upgrade to the new fork and revalidate the database, rather than an actual disruption of data.
Significance: This gives us some signal that, up until the team chose to upgrade the node, most transactions were reaching this nodes mempool before being seen in blocks, which is considered healthy behavior, and that transactions were reaching both chains, which ensured most user traffic survived the fork.
Chain Statistics
I don’t have any good charts for these statistics, and analysis is still underway, however we were able to extract some early insights from a data dump of the relevant chain:
- A total of 846 blocks were produced on the pig chain
- The pig chain included a total of 8647 transactions
- The chicken chain included a total of 13904 transactions
- The longest gap between blocks on the chicken chain was 964 seconds (roughly 16 minutes)
- They had 8168 transactions in common, and only 479 transactions were included in the pig chain and not the chicken chain
- That means that only ~3.33% of user transactions didn’t make it on the winning chain
- IOG attempted to resubmit these, and they were all invalid
- 23 (0.16% of all transactions) were only outside the validity interval, and would have succeeded otherwise
- 107 (0.7% of all transactions) only had bad inputs, indicating either some input they depended on was already spent (or it was a chained transaction, and thus didn’t exist)
- 349 (2.4% of all transactions) both had an invalid input and were outside their validity interval
- More analysis on these transactions is needed
- Granted, this doesn’t include transactions that never made it to the network at all, such as for faulty 3rd party infrastructure between the user and the Cardano network
- IOG attempted to resubmit these, and they were all invalid
Classification and History
I’d like to share my personal taxonomy for classifying large scale disruptions in blockchain, along with some historical outages on other popular blockchains that give rise to this taxonomy. I formed this mental model shortly after the last incident I reported on, and it’s a shame I didn’t write it down then. It is an attempt to hold myself accountable to the facts and avoid confirmation bias about the chain I’ve chosen to build my career around.
First, here is my personal definitions of the term “soft fork” and “hard fork”:
- A “soft fork” is any difference in consensus where the set of accepted blocks by one chain is a superset of the accepted blocks on another chain; In this case, usually nakamoto consensus has the chance to recover because if the subset chain overtakes the superset chain, the superset nodes will automatically switch. Most often, people also attach a temporal direction to this: a soft fork is when the newer nodes accept a subset of the blocks of the older nodes. But I don’t find it useful to restrict my definition in this way, and indeed, what we saw here is the older nodes being the more restrictive ones, but we still benefitted from this property.
- A “hard fork”, then, is any difference in consensus where the set of accepted blocks between two forks is incomparable: there are blocks that would be accepted by one and not the other, and vice versa. This prevents the nodes from ever converging without manual intervention.
These categories are sorted from those I consider the most serious to least (though the ordering at the end is far more arguable / negotiable).
Sovereignty Violation
Any bug or exploit that leads to remote code execution, forged signatures, repossessed funds in the ledger, or the like. This is a violation of the core sovereignty and safety of the chain itself.
Consequence: Complete loss of trust; Likely irrecoverable.
Example: No known examples on major L1s. Bitcoin came close in 2018, with CVE-2018-17144 that would have allowed duplicate inputs, and in 2012 with a duplicate coinbase bug which could had theoretical signature forgery attack vectors. A future quantum attack on ECDSA would likely qualify, and impact many many chains.
Ledger Violation
Any bug that leads to a violation of the core ledger guarantees, for any length of time, that any human would reasonably conclude violated the intent of the chain.
Consequence: Severe loss of trust; Recoverable, on a case by case basis, but should involve extreme changes to engineering discipline to regain trust.
Example: In August of 2010, Bitcoin suffered a value overflow bug; This created ~184.4 billion BTC, nearly 9000 times the intended 21m supply cap. No reasonable person could argue this was in line with the spirit of the protocol.
This required a soft fork, where miners upgraded to a node version that rejected transactions with the overflow, and recovered 19 hours after the faulty transaction, with old node versions switching to the longest chain as it overtook the faulty one.
Consensus Violation / Hard Fork
Any bug that results in a central decision making body mandating (or effectively mandating through outsized leverage) a violation of the chain consensus, usually via a node version that forces a rollback to before some bad event, or a coordinated truncation of the chain, etc.
Consequence: Excusable/recoverable early in the blockchain’s lifecycle, less excusable as time progresses.
Example: The Ethereum DAO hack was a smart contract exploit that resulted in a special ledger rule to force a hard fork to a different consensus. The Ethereum Foundation and exchanges heavily influenced the miners to choose this fork.
Large Chain-reorg / Soft Fork
Any bug or network condition that results in an extended divergence of consensus on chain, but which ultimately heals itself organically or through social consensus, and has no explicit lasting impact on the node implementation. Exposes certain application types, such as bridges or exchanges, to financial risk through replay attacks or for being on the wrong fork.
Consequence: Recoverable, with heavy learnings from the incident, if extremely rare
Example: Polygon experienced several decently sized reorgs in 2023 and 2022; The incident described above also falls in this category.
Smart Contract exploit
A bug in a smart contract of a popular, widespread protocol that results in large monetary loss to users. Mostly the fault of the smart contract author, but usually some blame lies with the language constructs that made the bug difficult to avoid.
Consequence: Recoverable (for the L1), with concern depending on the bug.
Example: The list is endless these days…
Full Consensus Halt
Any bug or network condition that results in an extended complete halt of consensus; no nodes can make progress without manual human intervention.
Consequences: Recoverable, with concern; unacceptable if it repeatedly and regularly happened.
Example: Several examples from Solana; BSC Bridge exploit; Avalanche Gossip Bug.
Degradation of service
Any bug or network condition that results in wide-scale degradation of quality of service for end users.
Consequences: Recoverable
Example: Ethereum Shanghai DoS attack; SundaeSwap’s launch; Cardano Jan 2023 hiccup;
Classification of THIS incident
Given the above taxonomy, this was a Large chain reorg / soft fork that self repaired. It was serious, but not existential. There will be plenty of people who are eager to pounce on Cardano’s misfortune, mainly because the community has a tendency to be a bit pretentious when it comes to our uptime. I won’t try to waste my breath in futile narrative wars with them.
The real primary concern, outside of degradation of service for users, was in systems that were unaware of the chain fork and opened themselves up to replay attacks across both chains.
For example, suppose an exchange is on the wrong fork, and allows users to deposit funds to the exchange, sell them for another token, and withdraw them on anotherain. When the chain reorganized, that user would have extracted value from the exchange.
Analysis is still underway to determine if this happened, but given the rapid response from exchanges, and the small number of transactions on the pig chain and not on the chicken chain, this currently seems unlikely to me.
What matters in the end is:
- Did the chain continue to make progress? (Yes)
- Was service degraded? (Yes)
- Were funds at risk? (Potentially)
- Did the Cardano network recover under essentially worst case conditions? (Yes)
- Would I have confidence to build my business on top of infrastructure that exhibited this level of robustness? (Yes)
The Good
Throughout this, Cardano’s engineering excellence and decentralization shined. Many decisions that some thought were overly paranoid proved their worth, and I personally learned a number of things about how Cardano operates and inoculates itself against forks like this that impressed me:
- I’m extremely glad that the node was implemented in a language that takes memory safety extremely seriously; The particular kind of bug, related to serializing out of buffers with improper bounds checking, in any other language could have been very serious. It would have been very easy in languages like C/C++, for example, for such a bug to enable arbitrary code execution. From there, it’s not hard to imagine someone extracting the private keys from many SPOs, gaining complete control of the chain and any funds that happened to be accessible from those keys.
- I’m extremely glad that IOG’s emphasis on high assurance engineering has largely prevented much more serious bugs. The fact that one slipped through after 8 years doesn’t nullify all of the effort that went to eliminate these kinds of bugs before they surface. Remember, no piece of software is perfect, and we only see the planes that survive.
- I’m extremely impressed with the reporting and monitoring infrastructure maintained by the founding entities. Being able to track the independent forks, the versions that people were on, the rates at which blocks were being produced, writing tools on-demand (this is where Amaru came in handy!), and the “canary transaction” infrastructure all gave critical and actionable insights throughout the fork that let us reach out to specific SPOs and shape our communication strategy
- I’m extremely impressed with the elegance of Ouroboros; I always knew about the “2160 rollback horizon”, which equates to about 12 hours worth of blocks; but the (un)common wisdom has been to wait 3 times as long (around 36 hours) for true finality. That always confused me, until this event. In the case of a partition, the chain density on both forks goes down. That means that each chain will take longer to reach a depth of 2160 blocks. This creates a natural self-regulation in times of stress, extending the length of the rollback horizon in proportion to the severity of the fork.
- I’m also impressed by the design of the networking stack, for a number of reasons:
- The warm/hot/cold peers system led to most nodes quickly finding peers that agreed with them
- As the chain density on the pig fork dropped, they reverted to a “safe mode”. In safe mode, nodes are more cautious about which nodes they trust, reverting to bootstrap peers and local trusted roots. Each SPO is able to specify their bootstrap peers and local trusted roots, putting them in control of the trusted backbone of the network. Since these nodes were more likely to have been upgraded in this case, it stopped the spread of pig chain blocks, lowering chain density further, and allowing the Cardano network to heal.
- The independence of the miniprotocols meant that even throughout, transactions nearly always propagated widely to all peers. This meant that even while the fork was ongoing, most user transactions could be included in both forks, and service was largely uninterrupted. This does emphasize the importance that certain application types program defensively in response to network partitions, chain forks, or lowered density, and there will likely be discussions in the coming days as to how to expose these metrics and design patterns better to guard against double spend risk
- I was impressed by the decentralization throughout our community, and not just as a buzzword. Our diversity of node versions was, paradoxically, both the source of the problem and helpful in the recovery. This problem wouldn’t occur if all nodes were identical, but it is impractical to expect total conformity in a distributed system of this scale. So, in the absence of that, the nodes still on the older (desired) version helped to stop the spread of the pig chain, and accelerate the recovery. In the future, diversity of implementations will also have a similar effect: higher risk that there is a difference of behavior, but lower risk that a bug in any one implementation can take out the whole network or chain.
- The communication infrastructure meant that thousands of SPOs were able to be notified, through a variety of different channels (discord, slack, telegram, email, twitter). The warroom was populated by members from many different organizations, including the founding entities, Intersect, technical thought leaders like Andrew Westberg, and representatives from exchanges, dApps, etc. No one entity made a unilateral decision about which fork to endorse, as many were involved in that discussion.
There’s a lot more to be impressed by, but these were the stand-outs for me!
The Bad
That being said, I promised I wouldn’t shy away from where Cardano fell short. Here are places where this incident highlighted areas where we can focus on:
- Anecdotally, many users had more frustrating experiences than the canary tests would imply. I would love to see the Cardano Foundation improve this, and partner with ecosystem infrastructure (like blockfrost or wallets) to improve our tracking of the typical “user experience” at any given time
- It seems like most or all of our chain explorers depend on cardano-db-sync, which can blind us when a bug impacts a single component. I’d love to see more diversity in architecture from these tools
- The fact that this bug appeared at all is a failure of our testing rigor; This is one area that historically Cardano has really shined, but I suspect (and I’m purely speculating here) that the intense ramping up of pressure to deliver governance and other features over the last year and a half has pulled attention away from these efforts.
- Similarly, I think Sebastien has the right idea with regards to doing codegen and fuzzing from the spec, rather than generating a spec from the implementation.
- This is going to be extra pertinent to two different projects Sundae Labs is working on; Amaru and Acropolis now have direct evidence of the importance of their testing rigor, and will need to be on high-alert for very subtle divergences between implementations. Such divergences have a higher chance of being hard forks rather than soft forks, because of the completely different stack of decisions. Here, the Sebastian (with an a) leads the great cardano-blueprint initiative in an effort to document and specify what it means to be a Cardano node.
- As mentioned above, I would like to see node to client miniprotocols that allow dApps, wallets, and exchanges to have better insight into the health of the chain/network; They should have easy APIs and official design patterns around circuit breakers and finality windows to make their apps more robust to such events.
- While the social consensus for which fork to choose was robust, I think it could be better. I imagine that some to many SPOs upgraded blind, based on trusting the recommendation of the founding entities alone, and without a clear understanding of the implications. In some obscure hypothetical scenarios, one could imagine this being used to fork the chain maliciously. I think we would only benefit from improved education about how Ouroboros works, what the implications are, and ensure that as many SPOs as possible are able to make informed decisions on tight timelines in such situations.
- To the above point, in a recent update video Charles Hoskinson called for a built-in pub/sub architecture. For those unaware, this is an extra protocol built into the network that enables broadcasting messages for a variety of use cases, leveraging the incredibly connected global network of Cardano nodes. Such a network would have allowed Intersect or others to broadcast to the SPOs on an emergency channel, alerting them of the urgent need to upgrade. I also believe this would be a good addition, and would unlock a lot of other opportunities for Cardano as well.
Conclusion
In the end, I believe you should assume every chain is likely one bad transaction away from a similar disruption, if you can but find the right incantation. Ask yourself, not for the sake of some Twitter argument, but truly for your own peace of mind, how would your favorite chain have stood up to such a breakdown in consensus? Personally, I’m coming away both impressed by Cardano, and with a personal To-do list for where I can put in the hard work to improve things even further.
